Asignatura: Arquitectura de la Información y Desarrollo Web Avanzado Titulación: Grado en Información y Documentación · UCM Profesor: Manuel Blázquez Ochando · manublaz@ucm.es · Despacho 103, 1.er piso
El presente programa fue aprobado por la Facultad de Ciencias de la Documentación. Por ello se mantienen los capítulos y contenidos definidos en el mismo. Como complemento al plan propuesto se proyectan nuevas clases prácticas que permiten al alumno aplicar los aspectos esenciales tanto de la arquitectura de la información como de la accesibilidad y usabilidad web.
Objetivos
Saber qué es la arquitectura de la información y cuáles son sus ámbitos de aplicación.
Saber organizar, clasificar y estructurar contenidos en un sitio web.
Aplicar los principios de usabilidad y accesibilidad al diseño de interfaces web.
Diseñar páginas web estáticas y enlazar ese conocimiento con el diseño de páginas web dinámicas.
Conocer cómo se estructuran contenidos científicos y profesionales en entornos digitales.
Definir el objeto, propósito y fines de un sistema de información o sitio web.
Determinar el público objetivo y realizar estudios de audiencia.
Realizar análisis competitivos de sitios web del mismo ámbito temático.
Diseñar la interacción usuario-sistema en el contexto de la arquitectura de la información.
Diseñar la navegación y los esquemas de organización de los contenidos.
Definir el etiquetado o rotulado de los contenidos para facilitar el acceso a la información.
Planificar, gestionar y desarrollar contenidos web.
Diseñar la interfaz de búsqueda y garantizar la facilidad de recuperación.
Evaluar la usabilidad y la accesibilidad de sitios web.
Analizar el feedback de los usuarios y aplicar procesos de re-ingeniería del sitio.
Actividades formativas
Clases teóricas, clases prácticas, tutorías específicas y trabajo no presencial del estudiante.
Las clases se imparten los miércoles y jueves de 15:00 a 16:30 horas. Habitualmente, uno de los dos días se dedica a teoría y el otro a prácticas.
Las prácticas tienen un plazo de entrega de entre 7 y 10 días, y deben subirse al apartado «Prácticas» del Campus Virtual. Este plazo es inapelable salvo causa de fuerza mayor debidamente justificada. No se acepta el envío de prácticas por correo electrónico.
Se valora positivamente una actitud proactiva, colaboradora, participativa y constructiva en el aula.
Evaluación
Resumen de la calificación
Examen: 50% · Prácticas: 40% · Participación en clase: 10%
Prácticas del curso (40%). Son obligatorias. El tipo principal de práctica es la Práctica Word: documento habilitado desde el blog con instrucciones y espacios para responder. El tiempo de corrección oscila entre 1 y 2 semanas desde la fecha de entrega.
Participación en clase (10%). Se valoran las aportaciones constructivas a los debates y a los contenidos impartidos, así como la resolución activa de problemas propuestos en el aula.
Examen (50%). Prueba de tipo test (30–40 preguntas) sobre todos los contenidos teóricos, prácticos y lecturas propuestas durante el curso. Las respuestas incorrectas penalizan 0,15 puntos.
Contenidos teóricos
Introducción a la asignatura.
Qué es la arquitectura de la información.
Necesidades de información y comportamiento del usuario.
Sistemas de organización de contenidos.
Sistemas de navegación.
Sistemas de búsqueda.
Herramientas para la edición web.
Planificación y desarrollo del sitio web basado en los principios de arquitectura de la información.
Diseño de estructuras web con capas y CSS: layouts.
Representación de resultados e interfaz de búsqueda.
Estilo de enlaces, menús y vinculación de archivos CSS.
Estructura de carpetas y archivos.
Maquetación de textos.
Cómo estructurar una página de contenidos.
Diseño de estructuras web: iframe vs. include.
Arquitectura de formularios y su adaptación dinámica.
Navegación dinámica vs. navegación estática.
Gestores de enlazamiento y redirección para la navegación.
Usabilidad web.
Contenidos prácticos
Editores para el desarrollo web avanzado: Eclipse y Adobe Dreamweaver.
Diseño de interfaz de un sitio web avanzado: Corel Paint Shop Pro.
Modelo de interacción cliente-servidor.
Los lenguajes de programación de la web estática: HTML, XML, XSL, CSS.
Programación web dinámica: PHP.
Diseño de una web dinámica avanzada.
Herramientas de utilidad.
Tutorías
Las tutorías presenciales se realizan los miércoles y jueves de 11:00 a 14:00 horas en el despacho 103 (1.er piso). Se ruega avisar previamente por correo electrónico a manublaz@ucm.es indicando el tema a tratar, con el fin de gestionar mejor la atención a todos los estudiantes. Al final de cada clase se reservan 15 minutos para resolver dudas sobre los contenidos impartidos.
Bibliografía básica
Aprender Dreamweaver CS4 con 100 ejercicios prácticos. Barcelona: Marcombo, 2009.
Diseño web para tod@s I: accesibilidad al contenido en la web. Barcelona: Icaria, 2007.
Diseño web para tod@s II: creando una web accesible. Barcelona: Icaria, 2007.
KRUG, S. Don't Make Me Think: A Common Sense Approach to Web Usability. New Riders, 2000.
NIELSEN, J. Usability Engineering. Morgan Kaufmann, 1993.
ROSENFELD, L.; MORVILLE, P. Information Architecture for the World Wide Web. 2.ª ed. O'Reilly, 2002.
SHNEIDERMAN, B.; PLAISANT, C. Designing the User Interface. Addison-Wesley, 2004.
TRAMULLAS, J. Planteamiento y componentes de la disciplina Information Design. Congreso universitario de Ciencias de la Documentación, 2000. Disponible en: tramullas.com/ai/concepto.pdf
VAN DIJCK, P. Information Architecture for Designers. Rotovision, 2003.
WODTKE, C. Information Architecture: Blueprints for the Web. New Riders, 2002.
00
Introducción: Arquitectura de la Información y Desarrollo Web
📅 19 sep 2011Introducción
La arquitectura de la información puede definirse como la técnica y metodología que permiten la construcción y edificación de productos informativos y documentales. Esto significa que el orden, la presentación y la pertinencia de los datos y contenidos publicados en muy diversos medios y soportes son los factores que intervienen directamente en esta disciplina. Su objetivo fundamental es facilitar la lectura y comprensión de tales contenidos para cada tipo de usuario, anticipándose al planteamiento de sus necesidades informativas.
Es frecuente observar el término arquitectura de la información relacionado con la construcción de sitios web y documentos electrónicos (MARTÍN FERNÁNDEZ, F.J.; HASSAN MONTERO, Y. 2003). Esta acepción, más moderna, continúa en constante evolución en cuanto a su alcance, ya que se entronca directamente con el segundo apartado central de la asignatura: el Desarrollo Web Avanzado. La gran cantidad de cambios y progresos a los que se viene sometiendo la web dinámica hace que los tipos documentales con los que se clasifican los contenidos queden obsoletos rápidamente. Gracias a la capacidad de reinvención e interpretación de la realidad, se descubren nuevos métodos de comunicación, representación y visualización de la información, y en definitiva documentos cada vez más elaborados, con mayor significado contextual y más complejos en cuanto a su programación y edificación.
De esta forma, la arquitectura de la información trata de aportar una manera de actuar, trabajar y programar la información en los distintos tipos documentales, en especial en aquellos consultados desde la red. La dimensión multiplicadora de los documentos electrónicos y su universalidad para su redifusión hace que el acceso, la facilidad de uso, la legibilidad, la claridad del diseño y la esquematización, la correcta narración, la propiedad del lenguaje y la semántica de los términos utilizados en los textos (HASSAN MONTERO, Y. 2002) sean propiedades clave de nuestra materia.
Figura 1. Mapa conceptual de la asignatura Arquitectura de la Información y Desarrollo Web Avanzado
HASSAN MONTERO, Y. 2002. Cómo leen los usuarios en la Web. Disponible en: nosolousabilidad.com
HASSAN, Y.; MARTÍN FERNÁNDEZ, F.J.; IAZZA, G. 2004. Diseño Web Centrado en el Usuario: Usabilidad y Arquitectura de la Información. En: Hipertext, n. 2. Disponible en: hipertext.net/web/pag206.htm
01
Arquitectura de la Información: fundamentos y dimensiones
📅 19 sep 2011Arquitectura de la Información
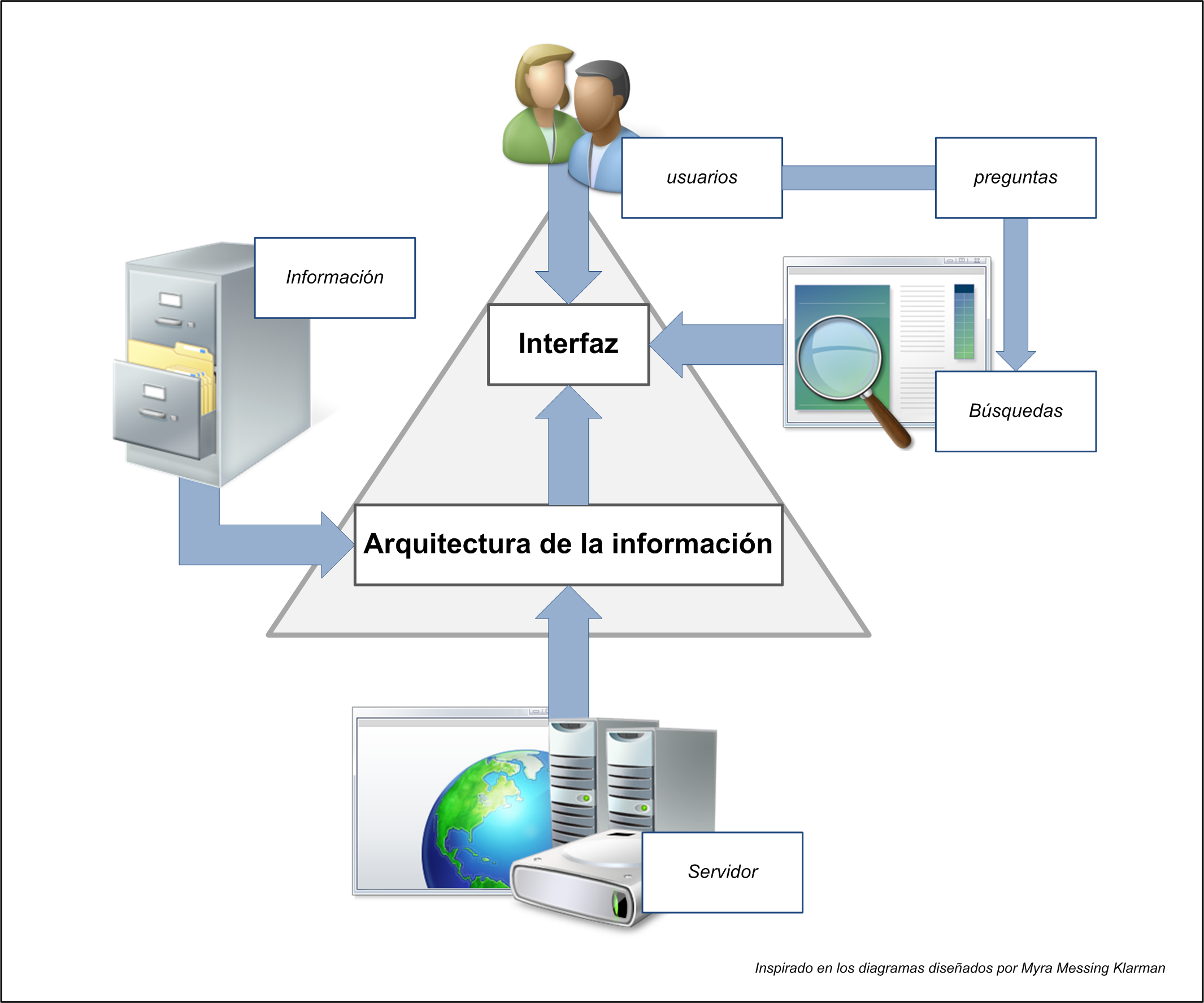
La arquitectura de la información es una disciplina que tiene como objetivo la estructuración, organización y etiquetado de los contenidos de un sistema de información o de un sitio web para facilitar su acceso y comprensión por parte de los usuarios. En el contexto de la web, esta disciplina se ocupa de cómo se organiza la información, cómo se navega por ella, cómo se etiqueta y cómo se busca.
Peter Morville y Louis Rosenfeld, en su obra seminal Information Architecture for the World Wide Web (O'Reilly, 1998; 4.ª ed. 2015), identificaron cuatro componentes fundamentales de la arquitectura de la información para la web:
Sistema de organización: Cómo se agrupa y categoriza la información. Existen distintos esquemas de organización: alfabéticos, cronológicos, geográficos, por temas, por audiencia, por tarea o de forma ambigua (por metáfora, etc.). La elección del esquema condiciona profundamente la experiencia del usuario.
Sistema de etiquetado: Cómo se representa la información. Las etiquetas son los términos o iconos que designan los contenidos y permiten identificarlos. Deben ser consistentes, precisas y comprensibles para el usuario objetivo.
Sistema de navegación: Cómo se desplaza el usuario por la información. La navegación puede ser global (menú principal), local (menú de sección), contextual (enlaces en el texto) o suplementaria (mapas del sitio, índices, guías).
Sistema de búsqueda: Cómo el usuario puede realizar búsquedas activas dentro del sistema. Incluye las interfaces de búsqueda, los algoritmos de recuperación, los resultados y su presentación.
Figura 2. Los cuatro sistemas fundamentales de la Arquitectura de la Información (Morville & Rosenfeld, 2015)
Figura. Conceptos de la arquitectura de la información
Figura. Entornos nativos de la arquitectura de la información
El contexto, los usuarios y el contenido
La arquitectura de la información no puede diseñarse de forma abstracta: siempre se produce en la intersección de tres factores interdependientes que Morville y Rosenfeld representan mediante su célebre diagrama circular:
El contexto: Los objetivos del negocio o la organización, la política interna, la cultura corporativa, los recursos disponibles y los condicionantes tecnológicos.
Los usuarios: Sus necesidades, comportamientos, modelos mentales, vocabulario, experiencia previa y objetivos de uso.
El contenido: Su volumen, tipología, formato, estructura, metadatos, antigüedad y dinámica de actualización.
El diseño efectivo de la arquitectura de la información requiere una investigación profunda sobre cada uno de estos tres factores antes de proponer cualquier solución estructural.
02
Diseño de la organización de contenidos
📅 26 sep 2011Arquitectura de la Información
El diseño del sistema de organización consiste en determinar la manera en que se agrupan, clasifican y estructuran los contenidos de un sitio web o sistema de información. Una buena organización permite al usuario comprender rápidamente qué contiene el sistema y cómo encontrar lo que busca. Las decisiones de organización se articulan en dos dimensiones: los esquemas de organización y las estructuras de organización.
Figura. Cómo la experiencia del usuario transforma los servicios de información de un sitio web
Esquemas de organización
Los esquemas de organización definen los principios bajo los que se clasifica la información. Se distinguen dos grandes categorías:
Esquemas exactos: Permiten ubicar sin ambigüedad cada elemento. Incluyen el esquema alfabético (enciclopedias, índices, directorios), el esquema cronológico (noticias, blogs, hemerotecas digitales) y el esquema geográfico (guías de viaje, mapas interactivos).
Esquemas ambiguos: La clasificación depende de la interpretación del contenido y del contexto de uso. Son los más habituales y los más complejos de diseñar. Incluyen los esquemas temáticos (portales de contenidos), por audiencia (segmentación por tipo de usuario), por tarea (portales de servicios públicos) y por metáfora (interfaces que imitan entornos físicos conocidos).
Estructuras de organización
Las estructuras de organización definen la forma en que se relacionan los elementos entre sí dentro del esquema elegido:
Jerarquía (top-down): Es la estructura más utilizada en sitios web. Define relaciones padre-hijo entre categorías. Su diseño implica equilibrar la amplitud (número de opciones en cada nivel) y la profundidad (número de niveles). Se recomienda no superar los tres o cuatro niveles para evitar la desorientación del usuario.
Base de datos o estructura relacional (bottom-up): Especialmente adecuada para grandes volúmenes de contenido homogéneo, organizado mediante registros con campos normalizados (bases de datos bibliográficas, catálogos, repositorios digitales).
Hipertexto: Los contenidos se relacionan mediante enlaces arbitrarios, sin jerarquía predefinida. Adecuado para enciclopedias colaborativas (Wikipedia) y documentación técnica.
Estructura matricial: Los mismos contenidos pueden organizarse según múltiples dimensiones simultáneamente (temática, formato, fecha, audiencia), facilitando la navegación por facetas.
03
Diseño de la navegación
📅 3 oct 2011Arquitectura de la Información
El sistema de navegación es el conjunto de elementos que permiten al usuario desplazarse por la información del sitio web. Un buen sistema de navegación responde en todo momento a tres preguntas fundamentales que el usuario se plantea inconscientemente: ¿Dónde estoy?, ¿Dónde he estado? y ¿A dónde puedo ir?
Tipos de navegación
Navegación global
El menú de navegación global o principal está presente en todas las páginas del sitio web y ofrece acceso directo a las secciones más importantes del sistema. Debe situarse en una posición constante, habitualmente en la parte superior o lateral izquierda de la página. Sus etiquetas deben ser concisas, representativas y comprensibles para el usuario.
Navegación local
La navegación local ofrece acceso a los contenidos de una sección específica del sitio. Complementa la navegación global y se presenta solo en las páginas pertenecientes a esa sección, mostrando típicamente un índice o listado de subsecciones y documentos.
Navegación contextual
Son los enlaces que aparecen embebidos en el texto del contenido, relacionando el documento actual con otros contenidos del sitio que amplían, complementan o referencian la información presentada. Este tipo de navegación es especialmente valioso en documentación técnica, publicaciones académicas y wikis.
Navegación suplementaria
Incluye herramientas adicionales de orientación como el mapa del sitio (sitemap), el índice alfabético de contenidos, la guía de uso, las preguntas frecuentes (FAQ) y el rastro de migas de pan (breadcrumbs).
Breadcrumbs o «migas de pan»
Los breadcrumbs son una secuencia de enlaces que muestra la ruta jerárquica desde la página de inicio hasta la página actual. Ayudan al usuario a entender su posición en la estructura del sitio y a retroceder a categorías superiores sin necesidad de usar el botón «atrás» del navegador. Su uso es especialmente recomendable en sitios con jerarquías profundas.
<nav aria-label="Ruta de navegación">
<ol>
<li><a href="/">Inicio</a></li>
<li><a href="/documentacion/">Documentación</a></li>
<li aria-current="page">Recuperación de información</li>
</ol>
</nav>
Ejemplo de breadcrumb accesible con ARIA en HTML5
04
Diseño de etiquetado
📅 10 oct 2011Arquitectura de la Información
El sistema de etiquetado define el vocabulario que se utiliza para representar los contenidos del sitio web. Las etiquetas son los términos, frases e iconos que identifican las secciones, las categorías, los enlaces y los bloques de contenido. Un etiquetado deficiente es una de las causas más frecuentes de fracaso en la navegación y recuperación de información.
Principios del buen etiquetado
Consistencia: Usar el mismo término para el mismo concepto en todo el sitio. Si una sección se llama «Documentos», no llamarla «Archivos» en otro contexto.
Precisión: El término debe describir inequívocamente el contenido al que apunta. Evitar etiquetas vagas como «Más información» o «Haga clic aquí».
Brevedad: Las etiquetas deben ser lo más cortas posible, sin perder precisión. El usuario escanea la página buscando patrones, no lee etiquetas largas.
Comprensibilidad: Usar el vocabulario del usuario, no el de la organización o el técnico. Realizar investigación de usuarios (encuestas, card sorting) para identificar los términos que el público usa naturalmente.
Distinción: Cada etiqueta debe diferenciarse claramente de las demás. Evitar sinónimos y solapamientos semánticos entre categorías adyacentes.
Tipos de etiquetas
Etiquetas en encabezados: Títulos de secciones, páginas y bloques de contenido. Son las más importantes para la orientación del usuario.
Etiquetas en menús de navegación: Términos que identifican las secciones principales y locales del sitio.
Etiquetas en índices: Términos de un vocabulario controlado (tesauro, taxonomía) que permiten acceder a los contenidos por facetas.
Etiquetas iconográficas: Iconos que complementan o sustituyen al texto. Solo se usan sin texto cuando el icono es universalmente reconocible (por ejemplo, el icono de carrito de compra o de búsqueda).
05
Diseño del sistema de búsqueda interna
📅 10 oct 2011Arquitectura de la InformaciónBúsqueda
El sistema de búsqueda interna permite al usuario localizar información mediante consultas explícitas. Es especialmente importante en sitios con grandes volúmenes de contenido donde la navegación resulta insuficiente. El diseño del sistema de búsqueda abarca tres ámbitos: el diseño de la interfaz de consulta, la configuración del motor de búsqueda (indexación, algoritmo, relevancia) y la presentación de los resultados.
Estrategias de indexación
Antes de diseñar la interfaz, el arquitecto de la información debe definir qué contenidos serán indexados y cómo. Las principales estrategias son:
Indexación de todo el sitio: Se indexa la totalidad del contenido. Es la opción más exhaustiva, pero puede generar ruido documental si se incluyen páginas de navegación.
Indexación por zonas: Se seleccionan áreas concretas del sitio (por ejemplo, solo las páginas de artículos, excluyendo las de navegación y metainformación). Mejora la precisión de los resultados.
Indexación por audiencia: Los contenidos se indexan en función del tipo de usuario al que se dirigen.
Indexación por tema: Permite enfocar previamente la consulta a un área temática específica del corpus.
Indexación cronológica: Adecuada para contenidos organizados temporalmente, como noticias o publicaciones periódicas.
💡 Recomendación clave
Es crucial distinguir entre páginas de navegación y páginas de destino al configurar la indexación. Si el motor indexa en exceso las páginas de menú, los resultados se llenarán de opciones de navegación en lugar de contenido relevante. La indexación debe primar siempre las páginas de destino.
06
Sistemas de búsqueda: anatomía y algoritmos
📅 14 oct 2011Arquitectura de la InformaciónRecuperación de Información
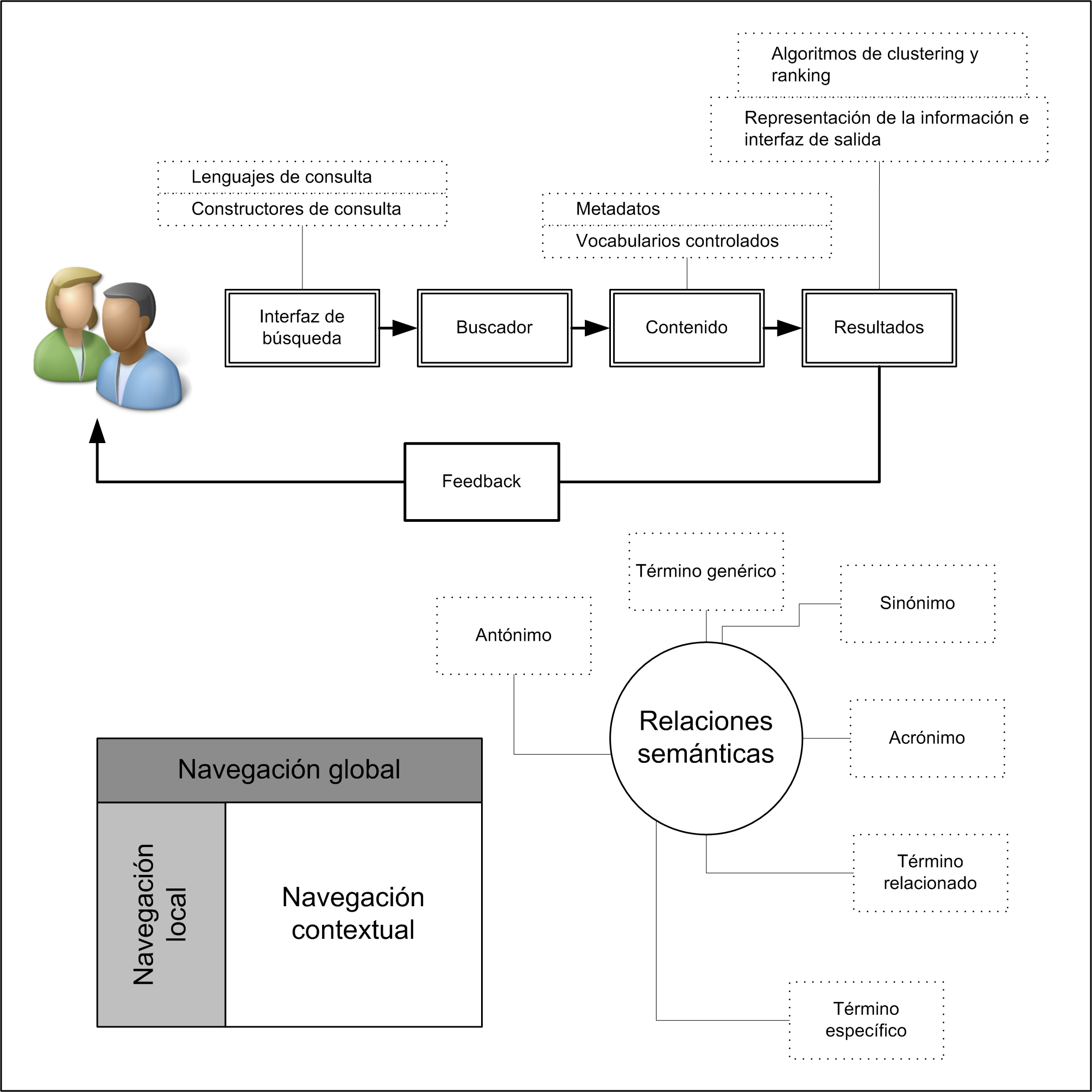
Un motor de búsqueda o buscador es un sistema complejo compuesto por múltiples módulos que trabajan coordinadamente para indexar contenidos y devolver resultados relevantes a las consultas de los usuarios. Comprender su anatomía es fundamental para cualquier profesional de la información que deba diseñar, implementar o evaluar sistemas de recuperación documental.
Componentes principales de un buscador
Figura 3. Arquitectura de un motor de búsqueda: pipeline de indexación y de consulta
Algoritmos de recuperación
Un algoritmo de recuperación de información es un método diseñado para localizar y ordenar documentos relevantes en respuesta a una consulta. Los algoritmos actúan conjuntamente con los indexadores, los analizadores léxicos y los módulos de representación de resultados. Se pueden clasificar en dos grandes categorías:
Algoritmos de reconocimiento de patrones
Su objetivo es determinar la coincidencia de patrones entre la consulta del usuario y el corpus textual indexado. Cuando se encuentran coincidencias, se recuperan los registros y se presentan los resultados mostrando el patrón de consulta y las distintas ocurrencias. Un ejemplo representativo son las expresiones regulares (REGEXP) o el reconocimiento de patrones mediante LIKE en bases de datos SQL.
Algoritmos de reformulación y precisión
Se basan en la relevancia de los resultados, su precisión y exhaustividad, devolviendo únicamente los resultados de mayor calidad. Esto se consigue mediante la aplicación de modelos booleanos, vectoriales, de similaridad y probabilísticos. El modelo TF-IDF (Term Frequency–Inverse Document Frequency) es uno de los más utilizados: pondera la importancia de cada término en un documento en función de su frecuencia en ese documento y de su rareza en el corpus global.
Generadores de consultas y asistencia al usuario
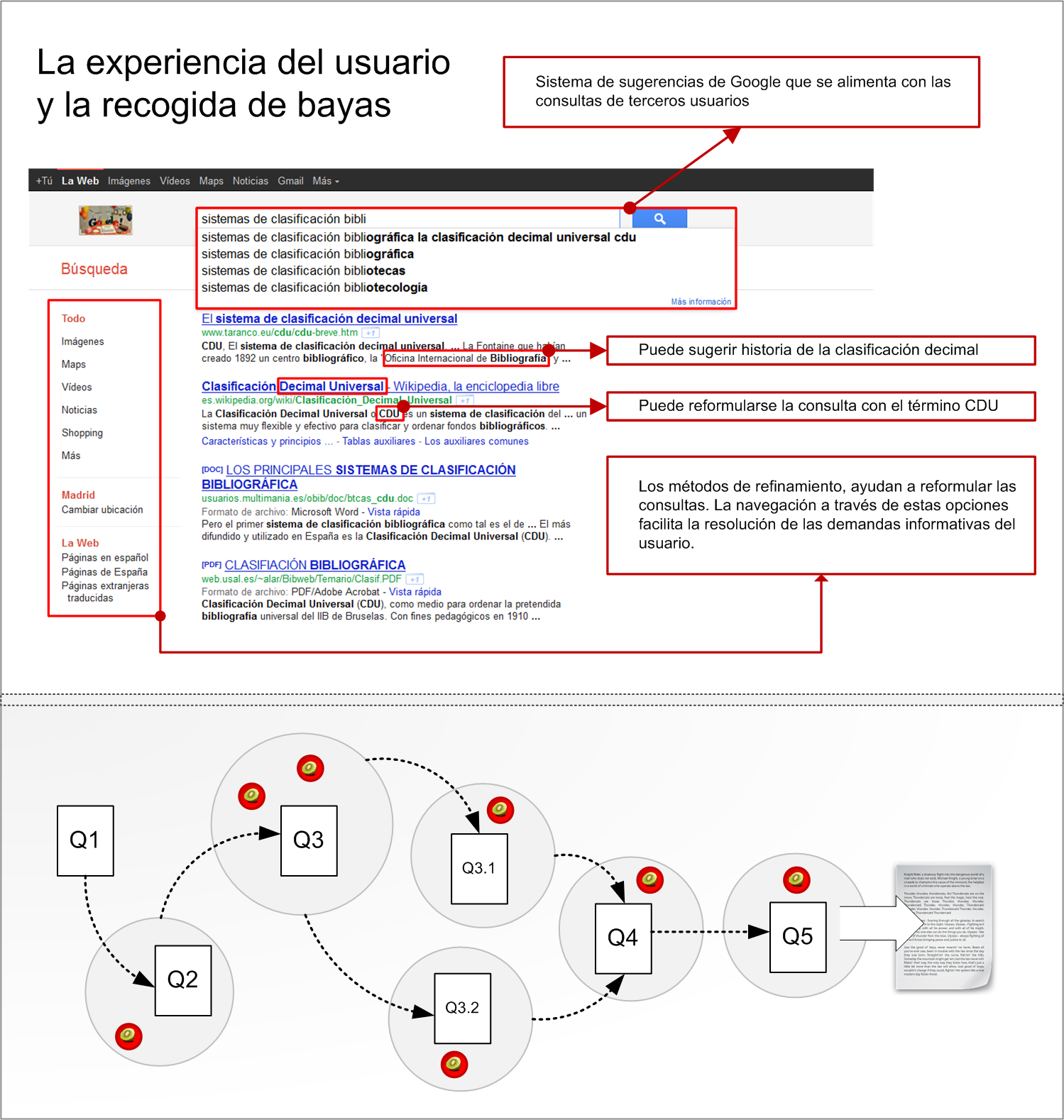
El algoritmo de búsqueda no es el único componente de un buscador completo. Son igualmente importantes las herramientas que ayudan al usuario a formular y refinar sus consultas:
Auto-sugerencias y corrección ortográfica: Cuando el usuario escribe un término incorrecto, el sistema sugiere la forma correcta para garantizar una recuperación satisfactoria.
Herramientas fonéticas: Determinan las equivalencias fonéticas de los términos de consulta para expandir la búsqueda y recuperar variantes ortográficas.
Stemming y lematización: A partir de la raíz morfológica de los términos, el sistema propone variantes derivadas, permitiendo recuperar documentos con distintas formas flexivas del mismo lema.
Procesamiento del lenguaje natural (PLN): Efectúa un análisis sintáctico de las consultas del usuario para determinar la estrategia de búsqueda óptima.
Vocabularios controlados y tesauros: Cuando el usuario introduce una cadena de consulta, el sistema sugiere términos controlados relacionados a partir del tesauro o taxonomía integrada.
Expansión de consulta: El sistema amplía automáticamente los términos introducidos con sinónimos, hiperónimos y términos relacionados para aumentar la exhaustividad de los resultados.
07
Diseño de estructuras web con capas y CSS: layouts
📅 27 oct 2011Desarrollo WebCSS
Para diseñar la estructura visual de una página web existen diversos enfoques técnicos. Su correcta elección determina la accesibilidad, el mantenimiento, la responsividad y la indexabilidad del sitio. A continuación se analizan los tres métodos principales y sus implicaciones desde la perspectiva de la arquitectura de la información.
Método 1: Marcos o frames (obsoleto)
El uso de marcos o frames implica el empleo de las etiquetas <frameset> y <frame> para dividir la pantalla en secciones independientes. Este modelo, muy popular en los primeros desarrollos de la web durante los años 1990, fue posteriormente desechado por múltiples razones:
Graves problemas de accesibilidad para lectores de pantalla y usuarios con discapacidad.
Dificultades de indexación por parte de los motores de búsqueda.
Imposibilidad de crear URLs únicas para cada estado de la aplicación.
Problemas de redimensionamiento en distintas resoluciones.
⚠️ Nota histórica
El elemento <frameset> quedó obsoleto en HTML5 y fue eliminado de la especificación. No debe utilizarse en ningún desarrollo moderno.
Método 2: Capas <div> con estilos CSS (estándar)
El uso de capas <div> o de elementos semánticos HTML5 (<header>, <nav>, <main>, <aside>, <footer>) combinado con propiedades CSS de posicionamiento (float, flexbox, grid) es el método estándar actual. Sus ventajas son:
Total control sobre el diseño visual y la adaptabilidad (responsive design).
Código fuente semántico, perfectamente indexable por los motores de búsqueda.
Separación clara entre estructura (HTML) y presentación (CSS).
Compatibilidad universal con todos los navegadores modernos.
El siguiente ejemplo muestra una estructura de dos columnas con la propiedad float:
Con la aparición de CSS Flexbox y CSS Grid, la construcción de layouts modernos se ha simplificado notablemente. El siguiente ejemplo muestra una estructura equivalente con Grid:
Los iframes (marcos incorporados) permiten embeber contenido externo o independiente dentro de una zona concreta de la página. A diferencia de los frames clásicos, los iframes no dividen la pantalla, sino que definen una ventana dentro de una capa <div>. Su uso en la actualidad se limita principalmente a la incrustación de contenidos de terceros (mapas, vídeos, formularios externos) y a ciertos patrones de aplicaciones web progresivas.
Modelos de disposición (layouts) con CSS
Los siguientes modelos ilustran las estructuras de página más habituales construidas exclusivamente con capas <div> y CSS. Pueden descargarse y estudiarse como punto de partida para el desarrollo propio:
Figura 4. Áreas clave de la estructura de un sitio web: cabecera, navegación, contenido, contextual y pie
08
Representación de resultados e interfaz de búsqueda
📅 21 oct 2011Arquitectura de la InformaciónRecuperación de Información
La interfaz de búsqueda es el conjunto de elementos que permiten al usuario formular una consulta y visualizar sus resultados. Su diseño requiere equilibrar las necesidades del usuario experto (que desea un control fino sobre la consulta) y el usuario ocasional (que prefiere la simplicidad). Una interfaz de búsqueda bien diseñada puede mejorar notablemente la tasa de satisfacción y reducir el número de búsquedas sin resultado.
Componentes de la interfaz de búsqueda
Caja de consulta
Es el espacio desde el que se transmite la petición del usuario en forma de cadena de texto. Siempre está acompañada de un botón que emite la orden de consulta, desencadenando todo el proceso de recuperación. El usuario suele asumir que basta con introducir los términos descriptivos de su necesidad informativa sin necesidad de operadores booleanos ni sintaxis especial. Por ello, el motor debe ser capaz de interpretar consultas en lenguaje natural. En cuanto al posicionamiento, un buscador general lo situará en lugar preferentemente central; en portales temáticos, se integra habitualmente en la barra de navegación global.
Búsqueda avanzada
Es una página o panel con funcionalidades avanzadas de control del motor de búsqueda. Permite al usuario especializado refinar una consulta para encontrar información más precisa: campos obligatorios o prohibidos, búsqueda por frase exacta, rango de fechas, idioma, formato de archivo, ámbito temático, etc. Aunque el porcentaje de usuarios que accede a la búsqueda avanzada es relativamente bajo, su disponibilidad es percibida positivamente y genera confianza en la calidad del sistema.
Repetición de la consulta original
La página de resultados debe mostrar de forma visible la cadena de consulta que el usuario introdujo. Esto sirve para recordar los términos usados y facilitar su reformulación sin necesidad de regresar a la página de inicio.
Cuando la búsqueda no devuelve resultados
Es esencial que el sistema proporcione retroalimentación útil cuando no se encuentran resultados. Las buenas prácticas incluyen: mostrar sugerencias de búsqueda alternativas, ofrecer términos relacionados, sugerir la eliminación de filtros restrictivos y facilitar el contacto con un servicio de ayuda. Una página de «0 resultados» sin orientación adicional es uno de los mayores problemas de experiencia de usuario en sistemas de recuperación.
Presentación de los resultados
Cada registro de resultado debe presentar un conjunto mínimo de elementos informativos que permitan al usuario evaluar su relevancia sin necesidad de acceder al documento completo. Para documentos textuales, se recomienda incluir: título enlazado, URL canónica, fragmento de texto con los términos de búsqueda resaltados (snippet), fecha de publicación y, opcionalmente, tipo de documento e idioma.
Figura 5. Anatomía de un resultado de búsqueda (snippet): título, URL, fragmento con términos resaltados y metadatos
09
Estilo de enlaces, menús y vinculación de archivos CSS
📅 27 oct 2011Desarrollo WebCSS
Estilo de los enlaces
Los enlaces constituyen la base de la hipertextualidad en el sitio web. Desde el punto de vista de la arquitectura de la información, deben proporcionar toda la información posible en relación a su título o descripción, idioma de la página de destino y contexto en el que será cargado el enlace. La sintaxis HTML5 completa de un enlace es la siguiente:
<a href="https://url-del-enlace"
target="_blank"
hreflang="es"
title="Descripción del recurso enlazado"
rel="noopener noreferrer">
Texto del enlace
</a>
Enlace en HTML5 con todos sus atributos semánticos y de seguridad
Para asignar estilos a los enlaces se necesita utilizar CSS y definir las propiedades para los cuatro posibles estados en los que puede encontrarse un enlace:
/* Estado normal: enlace no visitado */
a:link { color: #224a6a; font-size: 12px; }
/* Enlace ya visitado por el usuario */
a:visited { color: #236b6a; font-size: 12px; }
/* Cursor sobre el enlace (hover) */
a:hover { color: #4497da; text-decoration: underline; }
/* Enlace en el momento del clic (active) */
a:active { color: #44c5da; }
Los cuatro estados CSS de los enlaces (orden recomendado: LoVe-HA)
Cuando en una misma página conviven múltiples estilos de enlace (por ejemplo, enlaces del menú, enlaces del cuerpo del texto y enlaces del pie), se diferencia cada tipo mediante clases CSS:
/* Estilo para enlaces en el cuerpo del texto */
a:link.enlace-texto { color: #224a6a; }
a:visited.enlace-texto { color: #236b6a; }
a:hover.enlace-texto { color: #4497da; }
/* Estilo para enlaces en el menú de navegación */
a:link.enlace-menu { color: #ffffff; font-weight: bold; }
a:visited.enlace-menu { color: #ccddee; }
a:hover.enlace-menu { color: #ffd700; }
Diseño de menús con CSS
El diseño de menús con CSS puro ha sustituido a las antiguas soluciones basadas en imágenes, Java o Flash, que presentaban graves problemas de accesibilidad e indexabilidad. Los menús CSS se construyen sobre listas HTML ordenadas (<ol>) o desordenadas (<ul>) a las que se aplican estilos que transforman su presentación visual.
Desde un punto de vista de arquitectura de la información, los menús deben favorecer:
Una fácil lectura con contraste adecuado y tipografía clara.
Una correcta visibilidad y limpieza visual.
Coloraciones en tonos fríos, mates y no saturados que no compitan con el contenido.
Comportamiento coherente en todos los navegadores y resoluciones.
Los tres modelos fundamentales de menú son el menú horizontal (barra superior), el menú desplegable vertical y el menú lateral:
En la práctica real, los estilos CSS no se definen dentro de cada página HTML (inline o en la sección <head>), sino en archivos externos con extensión .css que se enlazan desde el documento HTML mediante la etiqueta <link>. Este método es fundamental para la mantenibilidad del sitio, ya que permite modificar el diseño de todas las páginas editando un único archivo de estilos.
Vinculación de múltiples archivos CSS externos: cada archivo se encarga de un aspecto del diseño
10
Estructura de carpetas y archivos
📅 3 nov 2011Desarrollo Web
La correcta estructuración de las carpetas y archivos del sitio web es un factor clave para su buena comprensión y gestión por parte de su administrador, desarrollador y arquitecto de la información. Tener unas convenciones básicas de nomenclatura es el principio de toda normalización y facilita enormemente el trabajo colaborativo y el mantenimiento a largo plazo.
Estructura de un sitio web estático
La estructura de un sitio web estático (compuesto exclusivamente por archivos HTML, CSS, JavaScript e imágenes, sin procesamiento en el servidor) sigue una organización canónica con las siguientes carpetas y archivos:
Elemento
Descripción
css/
Almacena todos los archivos de estilo CSS del sitio (estilos generales, tipografía, menús, formularios, etc.).
documents/
Se ubican todos los tipos de documentos descargables, archivos y páginas HTML de contenido.
images/
Se guardan todas las imágenes de tipo ilustrativo que acompañan al contenido editorial.
interface/
Se guardan todos los gráficos utilizados en el interfaz visual del sitio: iconos, botones, fondos de menú, etc.
java/
Carpeta en la que se guardan los archivos applet de Java (hoy en desuso).
index.html
Página principal e inicial del sitio web, desde la cual se accede a todos los contenidos.
Estructura de un sitio web dinámico
Cuando se desarrolla un sitio web dinámico —especialmente con lenguaje PHP, Python o Node.js— la organización de los contenidos es notablemente más compleja. Se crean carpetas específicas para funciones básicas del sitio, módulos y extensiones, y archivos de instalación y configuración. Una convención de nomenclatura recomendada es el uso de prefijos en los nombres de los archivos para identificar su tipología: func.nombre.php para funciones, mod.nombre.php para módulos.
Carpeta/Archivo
Descripción
css/
Archivos de estilo CSS.
documents/
Documentos y páginas HTML de contenido.
images/
Imágenes ilustrativas.
interface/
Gráficos de interfaz.
functions/
Funciones básicas del sitio: login, búsqueda, edición, gestión de contenidos. Prefijo recomendado: func.nombre.php.
modules/
Módulos y extensiones adicionales (traducción, gestor de plantillas, webFTP…). Prefijo recomendado: mod.nombre.php.
install/
Archivos necesarios para el proceso de instalación y configuración inicial del sistema (habitual en CMS).
index.php
Página principal en PHP, punto de entrada a todos los contenidos del sitio dinámico.
11
Maquetación de textos con CSS
📅 3 nov 2011Desarrollo WebCSS
La maquetación de textos es uno de los aspectos fundamentales del desarrollo web desde la perspectiva de la arquitectura de la información y la usabilidad. Una correcta definición de las propiedades tipográficas y de espaciado determina directamente la legibilidad y la experiencia de lectura del usuario. A continuación se presentan las principales propiedades CSS para el control de textos.
Propiedades del texto
Se recomienda utilizar los siguientes atributos para garantizar la legibilidad. Las fuentes deben elegirse de entre las familias tipográficas bien soportadas en los sistemas operativos más comunes:
/* Clase de texto para contenido editorial */
.texto {
font-family: Georgia, 'Times New Roman', serif;
font-size: 16px; /* o 1rem */font-weight: normal; /* o bold para énfasis */font-style: normal; /* o italic */line-height: 1.75; /* interlineado; 1.5–1.8 recomendado */color: #1f2937; /* gris oscuro, no negro puro */
}
Encapsulado de textos en capas
Una regla de oro para el control de los textos y contenidos del sitio web es su encapsulado dentro de una capa <div>. Si se desea aplicar un estilo determinado a un texto, es necesario encapsularlo previamente en un contenedor con una clase CSS asignada. Este método es aplicable a cualquier elemento textual, imagen, lista e incluso tabla.
<div class="texto">
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
Etiam auctor consectetur nisl, nec viverra sapien tincidunt ornare.
</div>
Márgenes externos (margin) e internos (padding)
Todos los textos del sitio web deben constar de márgenes internos y externos adecuados. El espaciado mínimo recomendado en cada margen es de 10 px. El atributo margin controla el espacio exterior a la capa y el atributo padding el espacio interior entre el borde de la capa y su contenido:
La alineación de los textos, siempre que sea posible, deberá ser justificada a ambos márgenes para conferir una apariencia editorial limpia y profesional. El atributo text-align acepta los valores left, right, center y justify.
Imágenes y texto
Cuando el texto acompaña a imágenes, se necesita establecer un formato flotante para alinear ambos elementos. Se recomienda siempre añadir un margen exterior mínimo de 10 px para evitar que el texto quede pegado a la imagen:
<div>
<img src="blogs/images/figura01.jpg"
alt="Descripción de la imagen"
style="float: left; margin: 10px 15px 5px 0;">
<p>Texto que fluye alrededor de la imagen...</p>
</div>
<div style="clear: both;"></div> <!-- Cancelar flotante -->
Tablas con estilos CSS
Para toda tabla que se edite, se recomienda especificar el ancho máximo, el tipo y color del borde, y la separación colapsada. La cabecera de columnas (<th>) debe tener un estilo diferenciador respecto a las filas de datos (<td>):
Desde un punto de vista estructural, los sitios web se desarrollan a partir de capas que dividen las distintas áreas que los componen: encabezamiento, menú general, menú local, área de contenidos, navegación contextual y pie de página. En el presente artículo se aborda la forma de interacción, navegación y carga de los contenidos dentro de esa estructura, comparando dos métodos complementarios: el iframe y el include de PHP.
Método iframe
El método iframe (del inglés Incorporated Frame, marco incorporado) consiste en embeber un marco o ventana dentro del área de contenidos del sitio web, ocupando el 100 % del ancho y el alto disponible en ese espacio. De esta forma, todo el contenido del sitio web se carga en dicho espacio. Entre sus ventajas destacan:
El contenido cargado es independiente del resto de la página, ofreciendo gran flexibilidad para cargar documentos de cualquier tipo.
El método de enlazamiento es muy sencillo: el atributo target del enlace apunta al nombre del iframe para cargar el documento en él.
Sin embargo, presenta inconvenientes importantes desde el punto de vista de la arquitectura de la información:
Accesibilidad reducida para lectores de pantalla y tecnologías de apoyo.
Dificultad para gestionar la altura variable del contenido (es necesario definir una altura fija, lo que activa barras de desplazamiento internas).
Los contenidos cargados en el iframe no están integrados en el código fuente principal, lo que puede dificultar su indexación.
<!-- Estructura con iframe (ejemplo simplificado) -->
<div class="capa-menu">
<ol>
<li><a href="http://www.bne.es/" target="visor">Biblioteca Nacional de España</a></li>
<li><a href="http://www.loc.gov/" target="visor">The Library of Congress</a></li>
</ol>
</div>
<div class="capa-contenido">
<iframe src="bienvenida.html" name="visor"
style="width: 100%; height: 100%; border: 0;">
</iframe>
</div>
Estructura con iframe: los enlaces del menú cargan contenido en el iframe con nombre «visor»
Método include de PHP
El método include consiste en el empleo de la función include() del lenguaje PHP para incrustar páginas web en formato HTML o scripts en lenguaje PHP dentro de un archivo matriz. Esta capacidad de incluir el código fuente de distintas páginas web y combinarlo en una única página permite una estructuración perfecta del sitio web sin necesidad de emplear iframes.
La forma más común de componer la estructura del sitio web es crear un archivo matriz en PHP que contenga un include() por cada área de la estructura:
<?php// archivo matriz: index.php// ===========================include("inc/encabezado.php"); // Carga el código del encabezadoinclude("inc/menu.php"); // Carga el menú de navegación
echo "<div class='contenido'>Contenidos de esta sección</div>";
include("inc/pie.php"); // Carga el pie de página?>
Estructura modular con include: cada área de la página se gestiona en un archivo independiente
Las ventajas del método include son notables frente al iframe:
El código fuente resultante es un único documento HTML integrado, perfectamente accesible e indexable.
La altura de los contenidos es siempre natural, sin necesidad de barras de desplazamiento internas.
Cualquier modificación en un archivo incluido (menú, cabecera, pie) se refleja automáticamente en todas las páginas que lo incorporan.
Mayor control y flexibilidad para incluir lógica de programación en cada área.
💡 Equivalente moderno: componentes web y frameworks
En el desarrollo web actual, el concepto del include de PHP ha evolucionado hacia los componentes de frameworks como React, Vue o Angular, y hacia los Web Components estándar de HTML5. La idea subyacente es la misma: modularizar las distintas partes de la interfaz para facilitar su mantenimiento y reutilización.
14
Arquitectura de formularios y su adaptación dinámica
📅 1 dic 2011Desarrollo WebHTML5
Los formularios constituyen un elemento esencial en toda la arquitectura de comunicaciones y edición de un sitio web. Son empleados como recipiente para la recogida de datos del usuario y su modo de empleo más común es el envío de mensajes como método de contacto. Pero también se utilizan para otros cometidos de mayor complejidad: como sistema de selección y filtrado en un buscador, como campos de edición para un sistema de gestión documental, para enviar valores entre distintas páginas web o para implementar la adaptación dinámica de la interfaz al contexto del usuario.
Formularios estáticos
Un formulario estático es aquel cuyos campos y estructura son siempre los mismos, independientemente del contexto o del usuario. Sirven para recoger datos de forma sencilla y predecible. Los atributos más importantes de la etiqueta <form> son:
action: URL del script que procesará los datos del formulario.
method: Método de envío. GET añade los datos a la URL (adecuado para búsquedas y filtros); POST los envía en el cuerpo de la petición HTTP (adecuado para datos sensibles o voluminosos).
enctype: Tipo de codificación. Imprescindible usar multipart/form-data cuando el formulario incluye carga de archivos.
Formulario de contacto básico en HTML5 con validación nativa
Formularios dinámicos
Los formularios dinámicos adaptan sus campos y opciones en función del contexto del usuario, de sus selecciones previas o de datos recuperados de una base de datos. Este tipo de formularios es fundamental en sistemas de recuperación de información avanzados, donde los criterios de búsqueda disponibles dependen del tipo de colección seleccionada.
<?php// Conexión a la base de datos
$conn = new mysqli("localhost", "usuario", "contraseña", "mi_bd");
// Recuperar categorías disponibles
$result = $conn->query("SELECT id, nombre FROM categorias ORDER BY nombre");
echo "<select name='categoria'>";
while ($row = $result->fetch_assoc()) {
echo "<option value='" . $row['id'] . "'>" . $row['nombre'] . "</option>";
}
echo "</select>";
?>
Formulario dinámico: opciones de un select generadas desde la base de datos
Adaptación dinámica con JavaScript / jQuery
JavaScript (y la biblioteca jQuery) permite modificar los formularios en tiempo real sin recargar la página. Un patrón muy habitual consiste en mostrar u ocultar grupos de campos en función del valor seleccionado en un campo anterior:
// jQuery: mostrar campos adicionales según selección
$('#tipo-documento').on('change', function() {
if ($(this).val() === 'libro') {
$('#campos-libro').show();
$('#campos-articulo').hide();
} else if ($(this).val() === 'articulo') {
$('#campos-articulo').show();
$('#campos-libro').hide();
}
});
16
Gestores de enlazamiento y redirección
📅 15 dic 2011Desarrollo WebPHP
Un gestor de enlazamiento es un programa especializado en generar o reconstruir direcciones URL válidas a partir de variables, nombres de archivo, cadenas de texto, identificadores o patrones de enlace semántico (también llamados friendly links o URLs amigables). En sitios web dinámicos con PHP, resulta imprescindible implementar un gestor de enlazamiento cuando la arquitectura del sitio requiere que los enlaces no incluyan variables explícitas en la URL (tipo ?page=documento) sino rutas limpias y legibles como /documentos/titulo-del-articulo.
Tipos de enlace
Antes de implementar un gestor, es necesario identificar el tipo o modelo de enlace que se va a utilizar en el sitio web:
Modelo
Ejemplo
Características
A — Enlace directo
/documentos/documento001.html
URL estática, sin variables. Ideal para sitios pequeños.
B — Enlace con extensión dinámica
/documentos/documento001.php
Archivo PHP, URL legible.
C — Enlace con variable GET
/index.php?page=documento001
Variable GET con nombre del documento. Fácil de implementar.
D — Enlace con múltiples variables
/index.php?page=titulo&date=2011-12-15
Combina nombre y fecha para identificar el recurso.
E — Enlace semántico con ID
/index.php?id=42
Referencia por identificador de registro en base de datos.
F — Enlace amigable (friendly link)
/titulo-del-documento
Sin extensión ni variables. Óptimo para SEO y usabilidad.
Gestor de enlazamiento con variables GET (modelos C/D)
<?php// Gestor de enlazamiento para modelos C/D
if ($_GET['page'] != "") {
// CASO 1: Enlace desde la portada
if ($origin == "index") {
echo "<script>
window.location.href = 'documents/$_GET[page].php';
</script>";
}
// CASO 2: Enlace desde otro documento
elseif ($origin == "doc") {
echo "<script>
window.location.href = '$_GET[page].php';
</script>";
}
else {} // Sin redirección
}
?>
Gestor de enlazamiento para modelos C/D: redirección condicional según origen
Gestor de enlazamiento con enlaces amigables (modelo F)
Los enlaces amigables o friendly links no contienen extensión ni variables GET. La forma de interpretar la información del enlace requiere capturar la URL entrante mediante la variable de servidor $_SERVER['REQUEST_URI'] y la función pathinfo():
<?php// Captura de la URL entrante
$path_parts = pathinfo("$_SERVER[REQUEST_URI]");
// CASO 1: La página citante es la portada (index.php)
if ($path_parts[basename] == "index.php") {
// Portada cargada: no se requiere redirección
}
// CASO 2: El origen es la portada, el destino es un documento
elseif ($origin == "index") {
echo "<script>window.location.href='../documents/$path_parts[basename].php'</script>";
}
// CASO 3: El origen es otro documento
elseif ($origin == "doc") {
echo "<script>window.location.href='../$path_parts[basename].php'</script>";
}
else {} // Sin redirección?>
Las URIs amigables tienen múltiples ventajas desde la perspectiva de la arquitectura de la información y el SEO:
Son legibles y memorizables por los usuarios.
Proporcionan información implícita sobre el contenido de la página.
Mejoran el posicionamiento en motores de búsqueda.
Facilitan el análisis de accesos en los registros del servidor.
El concepto de usabilidad tiene su origen en los términos anglosajones usability (usabilidad), user-friendly (fácil de usar) y ease of use (facilidad de uso). Según la norma ISO 9126, la usabilidad se define como «la capacidad de un software de ser comprendido, aprendido, usado y ser atractivo para el usuario en condiciones específicas de uso». La norma ISO 9241, con un enfoque más próximo a la mercadotecnia, la define como «la eficacia, eficiencia y satisfacción con la que un producto permite alcanzar objetivos específicos a usuarios específicos en un contexto de uso específico».
«Usabilidad web es la simplificación necesaria de las funciones y contenidos de un sitio o página web en sus elementos denotativos y connotativos esenciales, de forma tal que su motivación, objeto, navegación y contenidos estén al alcance del usuario de forma clara y sencilla, visualmente y cognitivamente identificables, recuperables con inmediatez, expresados y concebidos con la inteligencia del diseñador y la experiencia del usuario.» — Blázquez Ochando, M.
El concepto de usabilidad según Steve Krug
Según Steve Krug (autor de Don't Make Me Think, 2002), la usabilidad consiste en evitar que el usuario tenga que pensar cómo acceder a los contenidos, con qué elementos debe interactuar o qué significan las opciones de navegación. La regla central de la usabilidad, según Krug, es «no me hagas pensar»: el sitio web debe ser lo suficientemente intuitivo como para que el usuario pueda orientarse y encontrar lo que necesita sin esfuerzo cognitivo adicional.
Qué nos hace pensar
Si el objetivo es reducir el esfuerzo cognitivo del usuario, hay que procurar que los botones parezcan realmente botones, que los enlaces sean claramente identificables como tales y que los términos utilizados sean concisos y directos. Un usuario tendrá que reflexionar más si encuentra en el sitio web sintagmas largos en los enlaces, botones con forma ambigua o texto decorado con subrayados que imitan a los hipervínculos sin serlo.
Cómo se utiliza realmente la web
Uno de los comportamientos más documentados en los estudios de usabilidad es que los usuarios no leen completamente las páginas web; en su lugar, las ojean (scan), centrando su atención en unos pocos elementos que deben ser suficientemente denotativos para tomar una decisión de continuar o regresar. Este comportamiento se debe a la necesidad de resolver rápidamente las necesidades informativas, economizar el tiempo disponible y reducir la frustración ante la sobreabundancia de información.
Principios y consideraciones de diseño
Jerarquía visual: Lo más importante debe destacar visualmente del resto. Los contenidos similares deben tener un estilo tipográfico homogéneo en todo el sitio. Los epígrafes de nivel superior deben diferenciarse claramente de los contenidos subordinados.
Claridad de los elementos interactivos: Dejar inequívocamente claro qué es un enlace y qué no lo es. Reducir el número de clics necesarios para alcanzar los contenidos más demandados. Un sitio web más horizontal (pocas jerarquías de navegación) es más fácil de usar que uno con muchos niveles verticales.
Eliminación de lo accesorio: Omitir palabras innecesarias y contenidos que no aporten valor real. Reducir el texto a su mínima expresión informativa. Las páginas más cortas y directas son más efectivas que las extensas.
Reducción del ruido visual: Minimizar los efectos visuales que distraigan la atención del usuario: líneas de puntos, subrayados excesivos, imágenes de fondo repetitivas, efectos de rollover estridentes o exceso de elementos decorativos en el interfaz.
Diseño de la navegación: Utilizar sistemas de navegación como los breadcrumbs, definir rutas de acceso a todos los contenidos mediante pocos niveles jerárquicos y garantizar que el usuario sepa siempre en qué parte del sitio se encuentra.
Convenciones reconocibles: Emplear elementos de diseño y nomenclatura ampliamente reconocidos por los usuarios (el icono de la lupa para búsqueda, la casa para inicio, el sobre para contacto, etc.). No reinventar interfaces sin justificación.
Evaluación de la usabilidad
El análisis de la usabilidad de un sitio web puede estructurarse en torno a seis preguntas que el usuario debe poder responder con un simple golpe de vista (five-second test):
¿Qué sitio es este? (Identificación del sitio web)
¿En qué página estoy? (Nombre de la página actual)
¿Cuáles son las principales secciones del sitio? (Menú global)
¿Qué opciones tengo en este nivel? (Navegación local)
¿Dónde estoy dentro de la estructura del sitio? (Breadcrumb o indicador «usted está aquí»)
¿Cómo puedo buscar algo? (Caja de búsqueda)
Figura 6. Las seis preguntas de la usabilidad: lo que el usuario debe poder responder en menos de cinco segundos
Bibliografía
GARRETT, J.J. 2011. The Elements of User Experience: User-Centered Design for the Web and Beyond. 2.ª ed. New Riders.
HASSAN, Y.; MARTÍN FERNÁNDEZ, F.J.; GHZALA, I. 2004. Diseño web centrado en el usuario: usabilidad y arquitectura de la información. Hipertext, n. 2. Disponible en: hipertext.net/web/pag206.htm
HOM, J. 1998. The Usability Methods Toolbox Handbook. Disponible en: idemployee.id.tue.nl
KRUG, S. 2002. Don't Make Me Think: A Common Sense Approach to Web Usability. Prentice Hall. [Trad. española: No me hagas pensar]
NIELSEN, J.; LORANGER, H. 2006. Prioritizing Web Usability. New Riders.
FLORÍA CORTÉS, A. 2000. Recopilación de métodos de usabilidad. SIDAR. Disponible en: sidar.org
P1
Práctica 1. Deconstrucción de un sitio web
📅 19 sep 2011Práctica
Teniendo en cuenta el método de trabajo utilizado a la hora de crear un proyecto de arquitectura de la información para un documento o sitio web, esta práctica propone efectuar la operación inversa: la deconstrucción. A partir de un sitio web académico ya existente, el estudiante deberá reconstruir analíticamente su arquitectura de la información, identificando todos los elementos que la componen.
Instrucciones
Selecciona una de las páginas web de tipo académico propuestas por el profesor y elabora un informe que incluya los cuatro elementos siguientes:
Bosquejo espacial: Representación esquemática de la estructura visual del sitio, con la ubicación de sus áreas principales (cabecera, navegación, contenido, pie).
Mapa de secciones: Esquema jerárquico de los apartados, secciones y principales contenidos del sitio.
Vocabulario controlado: Muestra del lenguaje controlado utilizado en el etiquetado, menús e índices del sitio web.
Inventario de metadatos: Relación de los metadatos empleados en las páginas principales del sitio, con un nivel mínimo de profundidad.
Práctica 2. Planificación y desarrollo del sitio web: primeros pasos
📅 20 oct 2011Práctica
En esta práctica se deberá concretar la temática del sitio web a desarrollar, el área de trabajo, las fuentes de información a utilizar, los contenidos previstos, la estructura de secciones, categorías, subcategorías, los vocabularios controlados y el bosquejo general del proyecto. De esta forma el marco de trabajo quedará definido desde el comienzo para las sucesivas prácticas de edición web.
Para cada subcategoría de contenidos definida en la Práctica 2, se deberá elaborar una página web simple en formato HTML y CSS teniendo en cuenta los principios expuestos en los artículos de maquetación de textos y estructuración de páginas de contenidos. El objetivo es la elaboración de páginas de contenidos lo más sencillas posibles, sin artificios visuales superfluos, con alta calidad tipográfica, máxima legibilidad y correcta maquetación, control de márgenes y jerarquía visual coherente.
Práctica 4. Construyendo la estructura del sitio web
📅 11 nov 2011Práctica
De acuerdo con lo que se viene explicando, uno de los métodos más efectivos para lograr una estructura de sitio web mantenible es el empleo de las funciones include() de PHP para introducir los distintos fragmentos que componen el código. En la Práctica 4 se construirá la estructura completa del sitio web conforme a este método modular.
Aunque el editor Eclipse PDT permite la edición del lenguaje PHP, será necesario utilizar un servidor Apache HTTP y un intérprete PHP para poder comprobar los resultados de la programación. Dado que en las aulas de la facultad no siempre es posible instalar software en los equipos, se recomienda el uso de una distribución portátil que no requiera instalación, denominada WAPACHE.
💡 ¿Qué es WAPACHE?
WAPACHE es un paquete que contiene el servidor Apache HTTP y el compilador PHP listos para ser utilizados desde cualquier memoria USB sin necesidad de instalación. El único inconveniente es que no incluye el sistema de bases de datos MySQL. Para pruebas que requieran MySQL, se recomienda usar XAMPP Portable, que sí incluye los tres componentes (Apache, PHP y MySQL) en una distribución portable.
Para preparar el entorno de trabajo con WAPACHE:
Descomprimir WAPACHE y cambiar el nombre de la carpeta extraída a wapache.
Ejecutar wapache/bin/Wapache.exe para iniciar el servidor.
Copiar la carpeta del proyecto web en wapache/htdocs/nombre-del-proyecto/.
Acceder al proyecto desde el navegador en http://localhost/nombre-del-proyecto/.
Práctica 5. Adaptación dinámica de las páginas de contenidos
📅 17 nov 2011Práctica
Hasta el momento se ha trabajado con páginas de contenido estáticas basadas en HTML. En esta práctica, esas páginas se adaptan para su integración en la estructura del sitio web dinámico en PHP. Tomando un contenido estático y la estructura creada en la Práctica 4, cada página de contenido se convierte en una página matriz que carga mediante include() el encabezado, los menús y el pie de página.
Ejemplo de adaptación
La siguiente tabla muestra cómo debe ser adaptada una página de contenidos estática al modelo dinámico con include(). El código fuente correspondiente a los textos e informaciones de la página se introduce entre el include del menú y el include del pie de página, que es el área de la estructura destinada al contenido.
<?php// Página de contenidos = Página matriz// ====================================include("inc.head.php");
include("inc.menu.php");
echo "
<div style='padding: 20px;'>
<h1>Titular del documento</h1>
<h2>Resumen</h2>
<div class='textos'>Texto del resumen</div>
<h2>Autor</h2>
<div class='textos'>Apellidos, Nombre</div>
<div class='textos'>Institución · Datos de filiación · Correo electrónico</div>
<h2>Tabla de contenidos</h2>
<div class='textos'>
<ol>
<li><a href='#p1' title='Apartado 1'>Apartado 1</a></li>
<li><a href='#p2' title='Apartado 2'>Apartado 2</a></li>
<li><a href='#p3' title='Apartado 3'>Apartado 3</a></li>
</ol>
</div>
<h2><a name='p1'>Apartado 1</a></h2>
<div class='textos'>Texto del apartado 1</div>
<h2><a name='p2'>Apartado 2</a></h2>
<div class='textos'>Texto del apartado 2</div>
<h2><a name='p3'>Apartado 3</a></h2>
<div class='textos'>Texto del apartado 3</div>
</div>
";
include("inc.foot.php");
?>
Tabla 1. Página de contenidos adaptada al modelo dinámico con include
Los tres archivos auxiliares incluidos (inc.head.php, inc.menu.php, inc.foot.php) contienen respectivamente el código del encabezado con los estilos CSS, el menú de navegación general y el pie de página con el cierre de <body> y <html>. Al modificar cualquiera de estos archivos, el cambio se propaga automáticamente a todas las páginas del sitio que los incluyan.
Práctica 6. Controlando la información de los formularios
📅 24 nov 2011Práctica
El control de la información transmitida por medio de formularios es una constante en el diseño y desarrollo de la interfaz de interacción con el usuario. Los formularios permiten el envío de los parámetros necesarios para el funcionamiento del sitio web: publicación de comentarios y entradas, envío de mensajes de contacto, parámetros para las opciones de búsqueda y recuperación de información, entre otros. En esta práctica se probarán y analizarán todos estos aspectos con PHP.
Conocido el método de enlazamiento y navegación dinámicos visto en la práctica anterior, el objetivo de esta práctica es incorporarlos al proyecto de sitio web y a la estructura diseñada en las prácticas anteriores. Será necesario enlazar las páginas de cada sección desde el menú general de forma dinámica, así como las distintas páginas de contenidos en las que están agrupadas.
Práctica 8. Gestión, redirección y construcción de enlaces
📅 15 dic 2011Práctica
En muchos casos el proceso de construcción de enlaces depende de la correcta obtención de información de la URL. Por ello, los distintos lenguajes de programación del lado del servidor disponen de funciones y rutinas diseñadas para captar tales datos y manejarlos según las necesidades de redirección. En resumen, se trata de gestionar los enlaces y diferenciar sus apartados para elaborar un proceso de redirección completamente automático. En la presente práctica se comprobará cómo funciona el gestor de enlazamiento para enlaces de tipo F y la importancia de dominar la información de las direcciones URL.
Una de las aplicaciones más importantes de cualquier sitio web es su sistema de recuperación de información. Con el objetivo de conocer y aproximarse al proceso de implementación y funcionamiento de un buscador básico, así como a sus particularidades de configuración, se propone la resolución de la presente práctica. El buscador a implementar utilizará MySQL con búsqueda FULLTEXT para indexar y recuperar el contenido textual de los documentos del sitio.
Uno de los enfoques de la usabilidad corresponde al comportamiento del usuario durante el proceso de navegación hasta la localización de los contenidos que resuelven su demanda informativa. Para experimentar el número de clics que el usuario realiza durante una búsqueda y evaluar la usabilidad de los menús de navegación global, local y contextual, se pueden llevar a cabo tests de usabilidad específicamente diseñados.
En el caso propuesto, se presenta un test experimental desarrollado expresamente para la asignatura, en el que se plantean a lo largo de 10 preguntas distintas consultas que el usuario deberá resolver en un minuto. Cada movimiento y enlace en el que hace clic es recopilado de forma que, al finalizar el test, puede ser analizado y estudiado desde un punto de vista cualitativo para extraer conclusiones sobre la eficacia de la arquitectura de navegación evaluada.
KRUG, S. (2014). Don't Make Me Think, Revisited. 3.ª ed. New Riders. ISBN 978-0-321-96551-6.
NIELSEN, J.; LORANGER, H. (2006). Prioritizing Web Usability. New Riders.
HASSAN MONTERO, Y.; MARTÍN FERNÁNDEZ, F.J.; IAZZA, G. (2004). Diseño Web Centrado en el Usuario: Usabilidad y Arquitectura de la Información. Hipertext, n. 2. Disponible en: hipertext.net
NORMAN, D. (2013). The Design of Everyday Things. Revised ed. Basic Books. ISBN 978-0-465-05065-9.
Recuperación de información
BAEZA-YATES, R.; RIBEIRO-NETO, B. (2011). Modern Information Retrieval. 2.ª ed. Addison-Wesley. ISBN 978-0-321-41691-9.
MANNING, C.D.; RAGHAVAN, P.; SCHÜTZE, H. (2008). Introduction to Information Retrieval. Cambridge University Press. Disponible en: nlp.stanford.edu/IR-book
ROWLEY, J.; HARTLEY, R. (2008). Organizing Knowledge. 4.ª ed. Ashgate. ISBN 978-0-754-64431-6.