La continua proliferación y crecimiento de la información publicada en la red hace necesario un conocimiento más profundo de las técnicas, herramientas y aplicaciones en recuperación de información. La producción documental digital ha experimentado un crecimiento exponencial desde la aparición de la web: millones de documentos, artículos, registros bibliográficos, noticias, datos de investigación y contenidos multimedia se generan y publican cada día en miles de repositorios, bases de datos y plataformas de publicación. Ante este volumen, el profesional de la información no puede limitarse a localizar documentos de forma manual; necesita comprender y dominar los sistemas que hacen posible la organización, indexación y recuperación automática a escala.
En este contexto, los sistemas de gestión de contenidos —también denominados CMS, como Joomla o Drupal— han contribuido a facilitar la organización de la información y a multiplicar el número de vías y medios de acceso a ella. En este mismo marco de trabajo se inscriben los sistemas de redifusión o sindicación de contenidos, así como las herramientas y modelos de recuperación de información que se estudian en esta asignatura.
Se consideran aplicaciones documentales en su sentido más amplio todas aquellas herramientas cognitivas de tipo clasificatorio, librario o informático que facilitan y ayudan al documentalista en su actividad profesional. No se trata únicamente de herramientas de búsqueda: incluyen también los procesos de tratamiento previo de la información (normalización, indexación, eliminación de ruido documental), los modelos de representación del conocimiento (vectores, ontologías, tesauros) y los sistemas que permiten explotar esa representación para ofrecer resultados pertinentes al usuario.
En el contexto de la recuperación de información que aborda esta asignatura, se consideran aplicaciones documentales los siguientes sistemas y metodologías:
Sistemas de redifusión y recuperación de información bibliográfica sindicada, como OrangeUP, que demuestran cómo los formatos XML pueden emplearse para transmitir y recuperar registros bibliográficos.
Sistemas de recuperación basados en técnicas de agrupación o clustering, como Carrot2, que organizan automáticamente los resultados de búsqueda en grupos temáticos coherentes sin necesidad de clasificación previa.
Metodología de consulta en bases de datos relacionales SQL, con especial énfasis en MySQL y sus capacidades de indexación y recuperación a texto completo (FULLTEXT).
Sistemas de recuperación con expansión de consulta (query expansion), que amplían automáticamente los términos de búsqueda para mejorar la exhaustividad de los resultados.
Sistemas de indexación y análisis de contenidos a gran escala, como IBM OmniFind, diseñados para entornos corporativos con grandes volúmenes documentales.
Motores de recuperación de alto rendimiento, como Apache Lucene y sus derivados (Solr, Elasticsearch), que constituyen la base tecnológica de la mayoría de los buscadores modernos.
Figura 1. Mapa conceptual de los sistemas estudiados en la asignatura
01
Programa de la Asignatura
📅 3 oct 2011Programa
Asignatura: Aplicaciones Documentales de la Recuperación de Información Máster: Gestión de la Documentación, Bibliotecas y Archivos · UCM Profesor: Manuel Blázquez Ochando
Objetivos
Diseño y uso de aplicaciones relacionadas con la búsqueda y recuperación de información, con especial atención a los entornos documentales, biblioteconómicos y archivísticos.
Manejo de aplicaciones de gestión de la información en bibliotecas y servicios documentales, desde los gestores de bases de datos SQL hasta los sistemas de sindicación y agrupación de contenidos.
Comprensión de los modelos matemáticos y estadísticos subyacentes a los sistemas de recuperación de información (modelo vectorial, TF-IDF, similaridad del coseno).
Capacidad para diseñar, configurar y evaluar un sistema de recuperación de información adaptado a un contexto documental específico.
Metodología
Clases teóricas y prácticas.
Evaluación
La evaluación del alumno se realizará a partir del conjunto de actividades llevadas a cabo en clase y fuera del aula.
Temario abreviado
Herramientas de difusión y recuperación de información
Técnicas de recuperación y web semántica
Temario expandido
Herramientas de difusión y recuperación de información
Recuperación de información en bases de datos — Introducción
Principios de SQL
Operaciones SQL esenciales
Recuperación avanzada con SQL (FULLTEXT)
Sindicación de contenidos y recuperación de información
Generación automática de canales RSS y MARC-XML
Recuperación de información en canales de sindicación
Recuperación por grupos: clustering
Recuperación masiva: expansión de consulta
Técnicas de recuperación y web semántica
Introducción y conceptos fundamentales
Construcción de índices
Modelos de recuperación de información
Recuperación de información para la empresa
Evaluación centrada en usuarios
02
Recuperación de Información en Bases de Datos
📅 4 oct 2011Recuperación en MySQL
¿Qué es una base de conocimiento?
Es cualquier colección o fondo documental que constituye el corpus de un sistema de recuperación de información. Habitualmente esta base de conocimiento se organiza y estructura en bases de datos para su mejor gestión, tratamiento y recuperación. Esto significa que una base de conocimiento puede ser desde un compendio de datos, cifras y cadenas de texto inconexas hasta documentos, referencias bibliográficas y compendios informativos y semánticos con plena significación.
En el ámbito de las Ciencias de la Documentación, la base de conocimiento es el sustrato sobre el que opera cualquier sistema de recuperación: un catálogo bibliográfico, un repositorio de artículos científicos, un archivo de expedientes administrativos o un conjunto de registros de autoridad son, todos ellos, bases de conocimiento susceptibles de ser gestionadas y explotadas con las técnicas que se estudian en esta asignatura.
¿Qué es una base de datos?
La base de datos es el sistema que posibilita la organización y estructuración de los contenidos en tablas y estas, a su vez, en campos, de tal forma que cada campo represente una característica o rasgo descriptivo de la información registrada. Cada tabla representa el dominio general que se está almacenando. Por ejemplo, una tabla de usuarios contendrá campos lógicos que definan, describan e identifiquen a cada usuario: nombre, apellidos, DNI, dirección, correo, website, teléfono, código postal, etc.
Dentro de las distintas tablas de una base de datos es posible encontrar relaciones evidentes, ampliando la magnitud de la información. Este es el caso de las bases de datos relacionales: la tabla de usuarios puede estar relacionada con la tabla de préstamos, en la que se registran los documentos que se les presta. Esta operación requiere un campo clave de relación —habitualmente denominado clave foránea o foreign key— que vincula el identificador del usuario con los datos del préstamo y el identificador del libro prestado. Este mecanismo permite que tablas independientes queden vinculadas y puedan ser contrastadas y filtradas conjuntamente mediante consultas SQL que empleen la cláusula JOIN.
Tipos de campos en MySQL
El diseño de los campos de una tabla es una decisión crítica para la eficiencia del sistema. Los tipos de datos más habituales en MySQL son:
INT / BIGINT — números enteros; ideal para identificadores y contadores.
VARCHAR(n) — cadena de texto de longitud variable hasta n caracteres; para campos como título, autor, ISBN.
TEXT / LONGTEXT — texto de longitud indefinida; para resúmenes, contenidos completos y campos FULLTEXT.
DATE / DATETIME — fechas y marcas de tiempo; para publicación, modificación, préstamo.
FLOAT / DECIMAL — números decimales; para puntuaciones de relevancia o precios.
BLOB — datos binarios; para almacenar imágenes o archivos adjuntos.
¿Qué es un gestor de bases de datos?
El manejo de las bases de datos habitualmente se lleva a cabo mediante comandos definidos en terminales especializados (shell en Linux, cmd en Windows). Estos comandos responden en su mayoría al lenguaje de consulta normalizado SQL (Structured Query Language), con el que la base de datos entiende qué debe hacer. Dado que este método requiere un tecleado continuo, se han desarrollado programas informáticos que proporcionan un interfaz gráfico para la edición, tratamiento y recuperación de la información. Estos programas se denominan gestores de bases de datos. Uno de los más conocidos y utilizados en el mundo es phpMyAdmin, diseñado especialmente para trabajar con bases de datos que emplean SQL.
Otras alternativas modernas al phpMyAdmin son MySQL Workbench (cliente de escritorio oficial de Oracle/MySQL), DBeaver (multiplataforma y multi-motor) o TablePlus, todas ellas con soporte para SQL completo y visualización de relaciones entre tablas.
¿Qué es MySQL?
MySQL es el sistema de gestión de bases de datos relacionales de código abierto más extendido del mundo. Desarrollado originalmente por MySQL AB y actualmente mantenido por Oracle Corporation, utiliza el lenguaje de consulta SQL y se emplea conjuntamente con PHP para crear la mayoría de las aplicaciones web. Normalmente actúa como componente esencial de los paradigmas de desarrollo web:
WAMP (Windows + Apache + MySQL + PHP)
LAMP (Linux + Apache + MySQL + PHP)
MAMP (macOS + Apache + MySQL + PHP)
Entre sus características más relevantes desde el punto de vista documental destacan:
Eliminación automática de palabras vacías (stopwords) durante la indexación.
Creación de fichero inverso (índice invertido) para búsquedas a texto completo.
Cálculo automático de frecuencias de término y aplicación del modelo TF-IDF.
Soporte para recuperación booleana, por lenguaje natural y con expansión de consulta.
Motor de almacenamiento InnoDB con soporte transaccional completo (ACID) y claves foráneas.
Motor MyISAM, más ligero, con soporte nativo para índices FULLTEXT (aunque InnoDB incorporó soporte FULLTEXT desde la versión 5.6).
¿Cómo se conecta a MySQL?
Para trabajar con MySQL se necesita instalarlo previamente mediante una distribución WAMP (XAMPP), LAMP o MAMP. Una vez instalado, se requieren los siguientes datos de conexión:
Nombre del servidor: dirección IP o nombre de dominio donde está instalado. En instalación local siempre es localhost (127.0.0.1).
Nombre de la base de datos: MySQL permite múltiples bases de datos simultáneas, por lo que es necesario indicar con cuál se trabaja.
Usuario y contraseña: en instalaciones locales de prueba, por convenio se utilizan root / root.
Puerto: por defecto MySQL escucha en el puerto 3306; solo es necesario especificarlo si se ha cambiado la configuración.
Ejemplo de conexión en PHP (sintaxis moderna con PDO):
La función mysql_connect() está obsoleta desde PHP 5.5 y eliminada en PHP 7. Se recomienda usar PDO (para múltiples motores de BD) o MySQLi (específico para MySQL). PDO permite además el uso de sentencias preparadas (prepared statements), que previenen ataques de inyección SQL.
03
Principios de SQL y Sintaxis Básica
📅 10 oct 2011Recuperación en MySQL
SQL (Structured Query Language) es un lenguaje de consulta estándar diseñado para operar sobre bases de datos relacionales. Aunque en el contexto de esta asignatura se utiliza principalmente MySQL, SQL es también el lenguaje nativo de Oracle, DB2, SQL Server, PostgreSQL y muchos otros sistemas. Las principales operaciones que SQL permite llevar a cabo son:
Ejecutar consultas y recuperar datos
Efectuar procesos de recuperación de información
Insertar, actualizar y eliminar registros
Crear nuevas bases de datos, tablas y campos
Establecer permisos de administración para los usuarios
Crear distintas vistas de una base de datos
Sintaxis básica de consulta
SELECTcamposFROMtablaWHEREcondición;
Estructura fundamental de consulta SQL
Siempre que se desea obtener datos de una consulta SQL se requiere: un selector de los campos que son objetivo de la búsqueda, la tabla en la que se desea buscar y las condiciones que deben cumplir los resultados. Ejemplo:
SELECTisbnFROMcatalogoWHEREautorLIKE '%bryson%';
Recuperar todos los ISBN del catálogo cuyo autor sea Bryson. Los porcentajes actúan como truncamiento.
Crear una base de datos
CREATE DATABASEbiblioteca;
El nombre debe estar en minúsculas, sin acentos ni símbolos; los espacios se sustituyen por guiones bajos.
Crear una tabla con campos
El diseño de la estructura de una tabla es fundamental para una buena recuperación. Se deben especificar el tipo de campo, su extensión y la codificación de caracteres:
CREATE TABLEusers (
idINTNOT NULL AUTO_INCREMENT, PRIMARY KEY(id),
nameVARCHAR(255) CHARACTER SETutf8mb4COLLATEutf8mb4_general_ci,
surnameVARCHAR(255) CHARACTER SETutf8mb4COLLATEutf8mb4_general_ci,
allvisitsLONGTEXTCHARACTER SETutf8mb4COLLATEutf8mb4_general_ci,
lastvisitVARCHAR(255) CHARACTER SETutf8mb4COLLATEutf8mb4_general_ci,
lastsessionVARCHAR(255) CHARACTER SETutf8mb4COLLATEutf8mb4_general_ci,
onlineVARCHAR(50) CHARACTER SETutf8mb4COLLATEutf8mb4_general_ci,
levelVARCHAR(255) CHARACTER SETutf8mb4COLLATEutf8mb4_general_ci,
usernameVARCHAR(255) CHARACTER SETutf8mb4COLLATEutf8mb4_general_ci,
passwordVARCHAR(255) CHARACTER SETutf8mb4COLLATEutf8mb4_general_ci,
emailVARCHAR(255) CHARACTER SETutf8mb4COLLATEutf8mb4_general_ci
) CHARACTER SETutf8mb4COLLATEutf8mb4_general_ci;
Nota: se recomienda usar utf8mb4 en lugar de utf8 para soporte completo de Unicode (incluidos emojis).
Insertar un nuevo registro
INSERT INTOusersSETname = 'nombre',
surname = 'apellidos',
allvisits = 'registro de todas las visitas',
lastvisit = 'última visita',
lastsession = 'última sesión',
online = 'estado',
level = 'nivel de acceso',
username = 'nombre de usuario',
password = 'contraseña hasheada',
email = 'correo@dominio.com';
⚠️ SeguridadLas contraseñas nunca deben almacenarse en texto plano. Utiliza siempre funciones de hash seguras como PASSWORD_BCRYPT en PHP o la función SHA2() de MySQL.
⚠️ PrecauciónNunca ejecutes DELETE sin cláusula WHERE, pues eliminaría todos los registros de la tabla.
04
Operaciones de Consulta SQL Esenciales
📅 10 oct 2011Recuperación en MySQL
En este apartado se exploran las posibilidades de consulta esenciales de SQL: el operador LIKE, el operador REGEXP (de comparación de cadenas) y los operadores booleanos AND, OR, XOR y NOT.
Operador LIKE
El operador LIKE efectúa una comparación de la cadena de consulta de forma absoluta a menos que se especifiquen caracteres comodín:
% — coincide con cualquier extensión y tipo de carácter delante o detrás de la cadena.
_ — coincide con exactamente 1 carácter de cualquier tipo.
-- Busca cualquier registro cuyo título contenga "cupe"-- (recuperación, irrecuperable, ocupe, desocupen...)SELECT * FROMcatalogoWHEREtituloLIKE '%cupe%';
-- Busca ISBN con estructura 978-84-????-???-5SELECT * FROMcatalogoWHEREisbnLIKE '978-84-____-___-5';
Operador AND ( && )
Recupera registros únicamente cuando todas las condiciones establecidas se verifican. Si alguna condición no se cumple, el registro no se incluye en los resultados.
Variante exclusiva del operador OR: recupera registros que cumplan una condición u otra, pero nunca ambas simultáneamente.
-- Recupera libros de arquitectura O de bibliotecas, pero no de "arquitectura de bibliotecas"SELECT * FROMcatalogoWHEREtematicaLIKE '%arquitectura%' XORtematicaLIKE '%bibliotecas%'
LIMIT 0, 30;
Operador NOT ( ! )
Se utiliza como operador de negación. Permite excluir registros que contengan determinado patrón.
-- Obras de Cervantes que NO contengan "quijote" en el títuloSELECT * FROMcatalogoWHEREautorLIKE '%cervantes%' ANDtituloNOT LIKE '%quijote%'
LIMIT 0, 30;
Operador REGEXP
REGEXP es un operador especializado en comparación de cadenas mediante expresiones regulares (Regular Expressions), que permiten afinar la consulta con mucha más precisión. Los caracteres especiales más comunes son:
. — cualquier carácter individual
^ — indica el inicio de la cadena
$ — indica el final de la cadena
^[A-Za-z]{5} — cinco letras cualquiera al inicio
^.*[0-9]{2}$ — cadena que termina en dos dígitos
-- Autores cuyo apellido empiece por Bal (Balzac, Balza, Balz...)SELECT * FROMcatalogoWHEREautorREGEXP '^Bal'
LIMIT 0, 30;
📚 Referencias sobre expresiones regulares
FRIEDL, J. (2006). Mastering Regular Expressions. O'Reilly Media.
RegExr — herramienta online para probar expresiones regulares.
Cláusulas SQL para Ordenar Resultados y Mostrar Valores Únicos: ORDER BY y SELECT DISTINCT
📅 10 oct 2011Recuperación en MySQL
Cláusula ORDER BY
La cláusula ORDER BY se utiliza para ordenar el resultado de la consulta conforme a una o más columnas. Permite ordenar de forma ascendente (ASC), descendente (DESC) u orden natural (numérico).
-- Orden ascendente por campo3 y descendente por campo4SELECTcampo1, campo2FROMtablaORDER BYcampo3ASC, campo4DESC;
-- Ejemplo: título ascendente, fecha descendenteSELECTtitulo, autorFROMcatalogoORDER BYfechaASC, tituloDESC;
Cuando los campos contienen valores numéricos almacenados como texto (VARCHAR), se puede forzar un orden numérico añadiendo +0 al nombre del campo:
-- Orden natural descendente (numérico) por campo1SELECT * FROMtablaORDER BYcampo1+0 DESC;
-- Orden natural ascendente campo1 y descendente campo2SELECT * FROMcatalogoORDER BYtitulo+0 ASC, fecha+0 DESC;
Cláusula SELECT DISTINCT
La cláusula SELECT DISTINCT permite seleccionar resultados cuyo valor en los campos indicados no sea duplicado. Es útil para obtener listas de valores únicos de un campo.
-- Valores únicos de un campoSELECT DISTINCTcampo1FROMtabla;
-- Ejemplo: autores únicos del catálogoSELECT DISTINCTautorFROMcatalogo;
-- Combinación de DISTINCT con múltiples campos y condiciónSELECT DISTINCTmateria, autor, tituloFROMcatalogoWHEREfechaLIKE '%2010%';
Selecciona registros del año 2010 cuyos valores en materia, autor y título no sean duplicados entre sí.
05
Práctica 1: Experimentando con SQL
📅 11 oct 2011Prácticas y trabajos
🔬 Descripción de la práctica
Aprendida la teoría esencial para efectuar consultas en MySQL, se propone la resolución de una práctica en la que se pondrán en práctica todos los conocimientos adquiridos. Se debe descargar un archivo SQL con estructura y datos correspondientes a un catálogo bibliográfico, instalarlo correctamente desde phpMyAdmin, incluir un campo de identificación autonumérico y responder a las preguntas y consultas planteadas.
Recuperación Avanzada con SQL: Índices FULLTEXT y TF-IDF
📅 17 oct 2011Recuperación en MySQL
MySQL dispone de una serie de funciones de recuperación de información para los campos definidos como de tipo FULLTEXT. Esto significa que MySQL es capaz de indexar el texto completo de los campos que el administrador le especifique, creando internamente un fichero inverso que calcula frecuencias y elimina palabras vacías. Todo ello ocurre de manera automática en el momento en que se almacena información.
Particularidades del método FULLTEXT
Eliminación de palabras vacías: MySQL incluye por defecto una lista de stopwords en inglés. Para incluir stopwords en español es necesario configurar la variable ft_stopword_file. Documentación oficial
Limitaciones: Los términos de consulta deben tener un mínimo de 4 caracteres (configurable con ft_min_word_len). Además, en modo de lenguaje natural se aplica un umbral de corte basado en la técnica de cortes de Luhn, eliminando los términos más frecuentes (HAPAX y palabras vacías).
Algoritmo TF-IDF en MySQL
MySQL utiliza un algoritmo de recuperación muy similar a la ponderación TF-IDF (Term Frequency — Inverse Document Frequency), una medida estadística que determina la importancia de una palabra dentro de un documento en relación con toda la colección:
TF (Term Frequency): Frecuencia de aparición del término en el documento. A mayor frecuencia, mayor peso.
IDF (Inverse Document Frequency): Inversamente proporcional al número de documentos que contienen el término. Los términos muy comunes reciben menor peso.
Figura 2. Cálculo de relevancia TF-IDF en MySQL FULLTEXT
Preparar la tabla para FULLTEXT
CREATE TABLEcomments (
idINTNOT NULL AUTO_INCREMENT, PRIMARY KEY(id),
titleTEXTCHARACTER SETutf8mb4COLLATEutf8mb4_general_ci,
userVARCHAR(255) CHARACTER SETutf8mb4COLLATEutf8mb4_general_ci,
dateVARCHAR(255) CHARACTER SETutf8mb4COLLATEutf8mb4_general_ci,
commentsLONGTEXTCHARACTER SETutf8mb4COLLATEutf8mb4_general_ci,
responsesLONGTEXTCHARACTER SETutf8mb4COLLATEutf8mb4_general_ci,
indexerLONGTEXTCHARACTER SETutf8mb4COLLATEutf8mb4_general_ci,
FULLTEXT(indexer)
) CHARACTER SETutf8mb4COLLATEutf8mb4_general_ci;
El campo indexer almacenará el contenido consolidado para indexación FULLTEXT. Se recomienda un único campo índice para mayor eficiencia.
Los resultados se clasifican automáticamente por orden de relevancia, basándose en: número de palabras del registro, palabras únicas, total de palabras en la colección y número de registros que contienen cada palabra (modelo vectorial).
Búsqueda booleana a texto completo
SELECT * FROMcatalogoWHEREMATCH(indexer)
AGAINST('+recuperacion -perdida documental >informacion <datos (biblioteca archivo) ~ruido tesis* "recuperacion de informacion"' IN BOOLEAN MODE);
Modificadores del modo booleano:
+término — AND: el término debe aparecer obligatoriamente.
-término — NOT: el término no debe aparecer.
término (sin signo) — OR: puede o no aparecer.
>término — Mayor peso en la relevancia.
<término — Menor peso en la relevancia.
(t1 t2 t3) — Los términos deben aparecer próximos entre sí.
~término — El término provoca ruido; se infrapondera.
término* — Truncamiento: coincide con cualquier palabra que empiece así.
"frase exacta" — Búsqueda por frase literal.
Búsqueda con expansión de consulta
Las consultas FULLTEXT también soportan el método de retroalimentación automática por relevancia (Blind Relevance Feedback). Funciona ejecutando dos consultas: la búsqueda original y una segunda búsqueda que concatena los términos de los documentos más representativos de la primera.
SELECT * FROMcatalogoWHEREMATCH(indexer)
AGAINST('recuperación información' WITH QUERY EXPANSION);
El campo temporal score almacena el coeficiente de relevancia para ordenar los resultados de mayor a menor pertinencia.
07
Práctica 2: Consultas FULLTEXT
📅 18 oct 2011Prácticas y trabajos
🔬 Descripción de la práctica
Conocida la sintaxis de consulta FULLTEXT, se propone la resolución de una práctica consistente en la experimentación con sentencias MATCH() AGAINST(). Se debe descargar un archivo SQL con estructura y datos de un servicio de información global, instalarlo correctamente desde phpMyAdmin y responder a las preguntas y consultas planteadas.
Con el objetivo de asentar los conocimientos adquiridos en consulta de datos y recuperación de información, se propone el desarrollo del siguiente ejercicio. Se debe descargar el archivo SQL con estructura y datos de un servicio de información global, instalarlo desde phpMyAdmin y responder a las preguntas planteadas.
Instalación de un entorno de desarrollo local (XAMPP)
Para llevar a cabo las prácticas fuera del horario de clase, se recomienda instalar XAMPP, una distribución libre que incluye Apache HTTP, PHP, MySQL y phpMyAdmin, disponible para Windows, Linux y macOS. Es la alternativa moderna y activamente mantenida a la antigua distribución AppServ.
Figura 3. Arquitectura de una pila XAMPP/WAMP para desarrollo local
Una vez instalado XAMPP e iniciados los servicios Apache y MySQL, se accede a phpMyAdmin en: http://localhost/phpmyadmin/. En instalaciones locales el usuario y contraseña son por defecto root / root (o en blanco en XAMPP).
09
Sistemas de Clustering: Recuperación por Agrupación de Documentos
📅 24 oct 2011Clustering
Los sistemas de clustering —o agrupación de documentos— son aquellos sistemas de recuperación que emplean algoritmos para agrupar automáticamente los documentos de una colección según sus similitudes semánticas y temáticas, sin necesidad de clasificación previa.
El concepto de categorización de documentos refiere al proceso de encontrar grupos dentro de una colección basándose en las similitudes existentes entre ellos, sin un conocimiento a priori de sus características. (GOLDENBERG, D., 2007)
Principales algoritmos de agrupación
1. Categorización por objeto
El objetivo es encontrar agrupaciones entre todos los documentos de la colección. Un porcentaje de términos relevantes de un grupo debe estar presente en todos y cada uno de los documentos que lo forman.
2. Representación vectorial
Cada documento se representa mediante vectores, caracterizados por la frecuencia de aparición de los términos más representativos. Los pasos del proceso son:
Cálculo del centroide: promedio de los vectores que componen el grupo.
Reducción de términos a su raíz (stemming).
Eliminación de palabras vacías (stopwords).
Eliminación de términos con bajo poder discriminatorio.
Eliminación de HAPAX (términos que aparecen una sola vez).
3. Similaridad documental
Consiste en medir la distancia entre los vectores de cada documento mediante:
Coeficiente del coseno: calcula el ángulo alfa entre vectores. Es el método más habitual.
Otros coeficientes: Jaccard, Distancia Euclídea, Coeficiente de Dice, Sorensen, Hamming, Tversky.
4. Métodos jerárquicos
Emplean algoritmos que caracterizan los documentos con una estructura arbórea denominada dendrograma. A partir de la raíz (un único grupo con todos los documentos), la división por grupos se produce analizando qué documento tiene mayor similitud con otro.
5. Métodos particionales
En vez de trabajar a varios niveles para crear una estructura arbórea, se trabaja a un solo nivel. El patrón de agrupación viene dado de antemano (p. ej., el conocido algoritmo k-means).
6. Mapas auto-organizados (SOM)
También denominados sistemas de redes neuronales (Self-Organizing Maps, de Kohonen), proyectan los documentos en un espacio bidimensional preservando las relaciones de similitud.
Figura 4. Representación esquemática del proceso de clustering de documentos
Un ejemplo de clustering: Carrot2
Carrot2 es un sistema de recuperación basado en técnicas de agrupación de documentos y contenidos web. Uno de sus algoritmos es el método jerárquico Lingo, capaz de agrupar automáticamente resultados de búsqueda de Google o Bing.
Algoritmos disponibles en Carrot2
Lingo: método jerárquico basado en factorización de matrices (NMF/SVD). El más preciso.
k-means: método particional. Rápido pero requiere especificar el número de grupos.
STC (Suffix Tree Clustering): basado en sufijos comunes entre los títulos de los documentos.
Opciones de visualización
Aduna Cluster Map: esquema relacional que muestra las relaciones entre grupos.
Circles Visualization: diagrama circular con los principales temas agrupados.
FoamTree Visualization: mapa de áreas coloreadas: tonos cálidos para grupos más relevantes, fríos para los menos relevantes.
Parámetros de configuración principales
Cluster count base: factor base para la creación de grupos.
Size-score sorting ratio: equilibrio entre tamaño del grupo (0) y puntuación de relevancia (1).
Term weighting: método de ponderación de términos (TF-IDF logarítmico, lineal o solo TF).
📚 Bibliografía
FIGUEROLA, C. G.; ALONSO BERROCAL, J. L.; ZAZO RODRÍGUEZ, A. F.; RODRÍGUEZ, E. (2002). Algunas técnicas de clasificación automática de documentos.
GOLDENBERG, D. (2007). Categorización automática de documentos con mapas auto-organizados de Kohonen. Tesis de Magíster, ITBA.
OSINSKI, S.; WEISS, D. (2005). A Concept-Driven Algorithm for Clustering Search Results. IEEE Intelligent Systems, 20(3), 48–54.
10
Práctica 4: Recuperación con Carrot2
📅 24 oct 2011Prácticas y trabajos
🔬 Descripción de la práctica
Las técnicas de agrupación de contenidos pueden ser de gran utilidad para la recuperación masiva de documentos y su clasificación automática. Para poner a prueba los conceptos aprendidos, se propone la resolución de una práctica basada en un caso real: recuperación de empresas especializadas en ingeniería.
Práctica 4bis: Recuperación con Carrot2 (modalidad online)
📅 25 oct 2011Prácticas y trabajos
🔬 Descripción de la práctica
Versión alternativa de la práctica 4 para estudiantes que no dispongan de ordenador personal o no puedan instalar el programa Carrot2. Puede realizarse en los ordenadores de la facultad o desde cualquier navegador web. Se propone una práctica basada en la colección de prueba ODP239.
Sindicación de Contenidos y Recuperación de Información
📅 31 oct 2011Sindicación de contenidos
La sindicación de contenidos —también denominada redifusión de contenidos— es una técnica ampliamente empleada para la transmisión y seguimiento de información publicada en la red. La gran cantidad de información que se genera diariamente en medios digitales hace necesario su conocimiento y explotación documental para su organización, clasificación y posterior recuperación.
Desde el punto de vista técnico, la sindicación de contenidos se basa en la generación automática de un archivo XML que describe los contenidos publicados por un sitio o sistema, incluyendo título, resumen, autor, fecha y enlace permanente de cada elemento. Este archivo —denominado feed o canal de sindicación— es generado automáticamente por el sistema publicador cada vez que se produce un nuevo contenido, y puede ser consumido por cualquier programa parser o lector de canales que comprenda el formato.
La relevancia de la sindicación de contenidos para las Ciencias de la Documentación va más allá de la mera suscripción a noticias. Sus implicaciones fundamentales son:
Selección y control de fuentes: permite al documentalista identificar y controlar de forma sistemática qué fuentes de información se incluyen en el corpus de recuperación.
Actualización automática: el sistema documental puede mantenerse al día sin intervención manual, capturando los nuevos contenidos en cuanto son publicados.
Interoperabilidad de formatos: el XML como base permite adaptar el canal a cualquier esquema documental (Dublin Core, MARC-XML, MODS, EAD, etc.).
Escala: un único sistema puede agregar y recuperar información de miles de fuentes simultáneamente, lo que sienta las bases de los buscadores especializados.
Comparativa de formatos de sindicación
📋 Tabla comparativa de formatos
Formato
Año
Base
Características
RSS 0.9/0.91
1997–1999
XML/RDF
Primera versión; solo titular y enlace
RSS 1.0
2000
RDF/XML
Basado en RDF; extensible con módulos; orientado a la web semántica
RSS 2.0
2002
XML
Más simple que RSS 1.0; ampliamente adoptado; soporta enclosures (podcasting)
ATOM 1.0
2005
XML (RFC 4287)
Estándar IETF; más riguroso que RSS; soporte nativo de internacionalización
MARC-XML
2002
XML (LOC)
Equivalente XML del formato MARC 21; para registros bibliográficos y de autoridad
JSON Feed
2017
JSON
Alternativa moderna basada en JSON; más ligero para consumo en APIs REST
MARC-XML como formato de sindicación documental
MARC-XML es el equivalente en XML del formato de intercambio bibliográfico MARC 21, desarrollado por la Biblioteca del Congreso de los Estados Unidos. Su estructura permite representar todos los campos y subcampos del formato MARC en un esquema XML válido y procesable por cualquier herramienta estándar de tratamiento XML. En el contexto de la sindicación documental, MARC-XML puede emplearse exactamente de la misma forma que RSS o ATOM: un generador produce el archivo XML con registros bibliográficos, y un parser lo consume, interpreta y almacena en la base de datos documental.
<?xml version="1.0" encoding="UTF-8"?><collectionxmlns="http://www.loc.gov/MARC21/slim"><record><leader>00000nam a2200000 i 4500</leader><datafieldtag="100" ind1="1" ind2=""><subfieldcode="a">Blázquez Ochando, Manuel</subfield></datafield><datafieldtag="245" ind1="1" ind2="0"><subfieldcode="a">Aplicaciones documentales de la recuperación de información</subfield></datafield><datafieldtag="520" ind1="" ind2=""><subfieldcode="a">Recursos docentes del Máster en Gestión de la Documentación, UCM.</subfield></datafield></record></collection>
Ejemplo de registro bibliográfico en formato MARC-XML
Evolución histórica de los formatos de sindicación
Figura 5. Cronograma de la evolución de los formatos de sindicación de contenidos
Cómo funciona la sindicación de contenidos
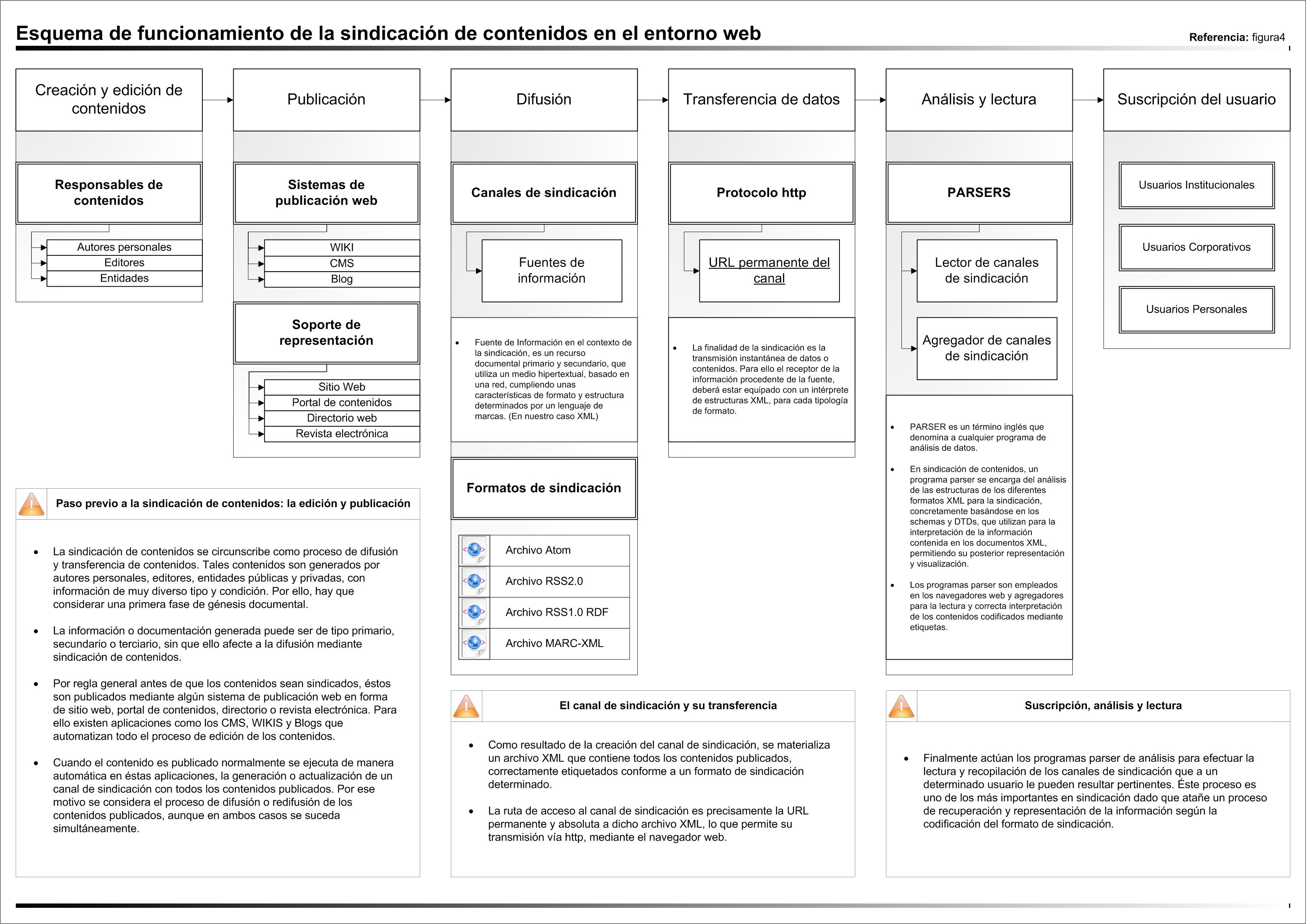
Figura 6. Esquema de funcionamiento de la sindicación de contenidos en el entorno web
Estructura de un canal de sindicación RSS 2.0
<?xml version="1.0" encoding="UTF-8"?><rssversion="2.0"><channel><title>Nombre del canal</title><link>https://ejemplo.com</link><description>Descripción del canal</description><language>es</language><item><title>Título del artículo</title><link>https://ejemplo.com/articulo</link><description>Resumen o contenido completo</description><pubDate>Mon, 31 Oct 2011 08:41:00 +0000</pubDate><guid>https://ejemplo.com/articulo#1</guid></item></channel></rss>
Anatomía básica de un canal RSS 2.0
Para ampliar los conceptos de sindicación, se ha desarrollado un documento de referencia que explica las bases técnicas y los fundamentos sobre los que se asienta esta técnica:
Cronograma de la evolución de los formatos de sindicación
Esquema de funcionamiento de la sindicación de contenidos en el entorno web
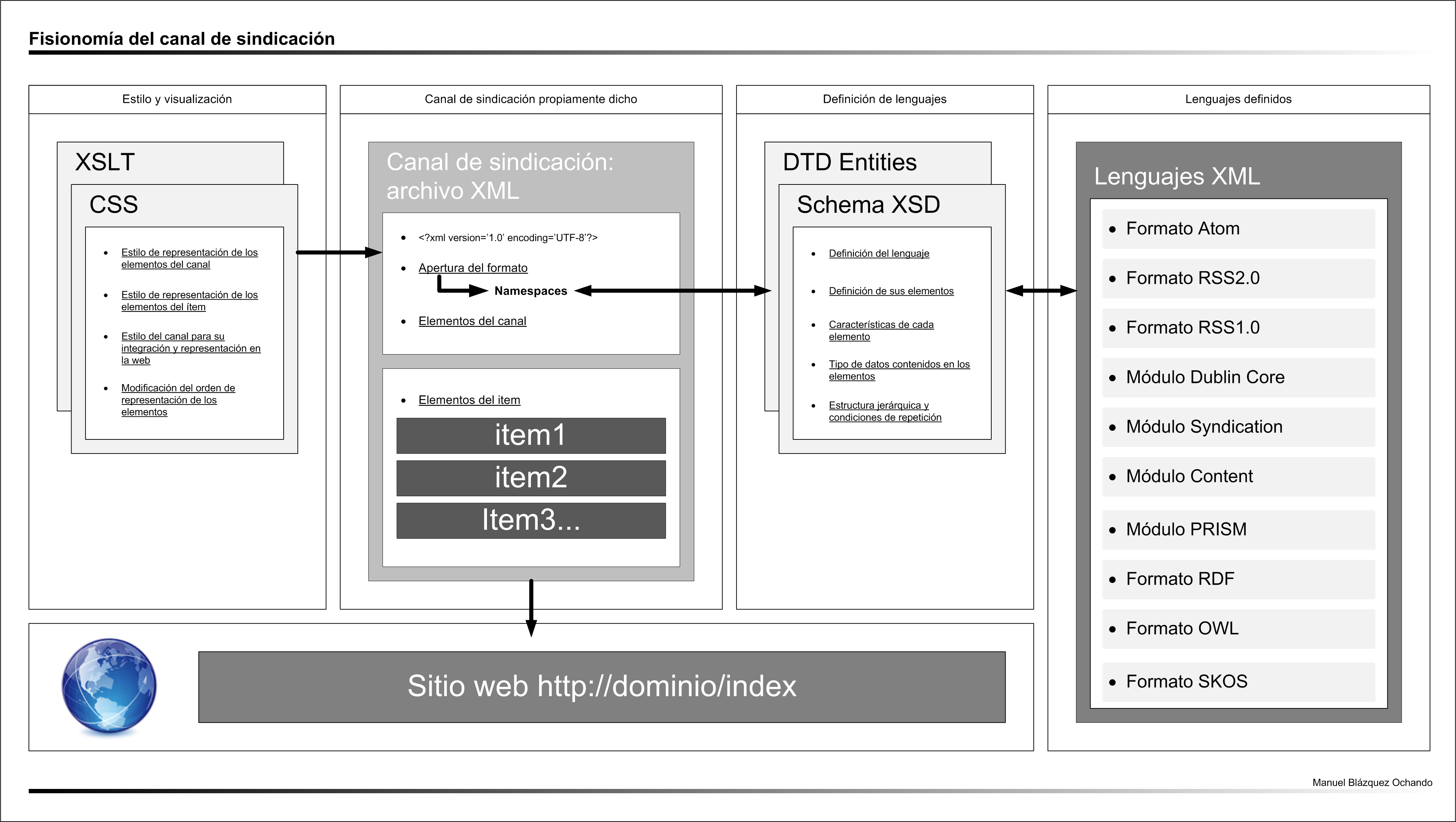
Fisionomía de un canal de sindicación
13
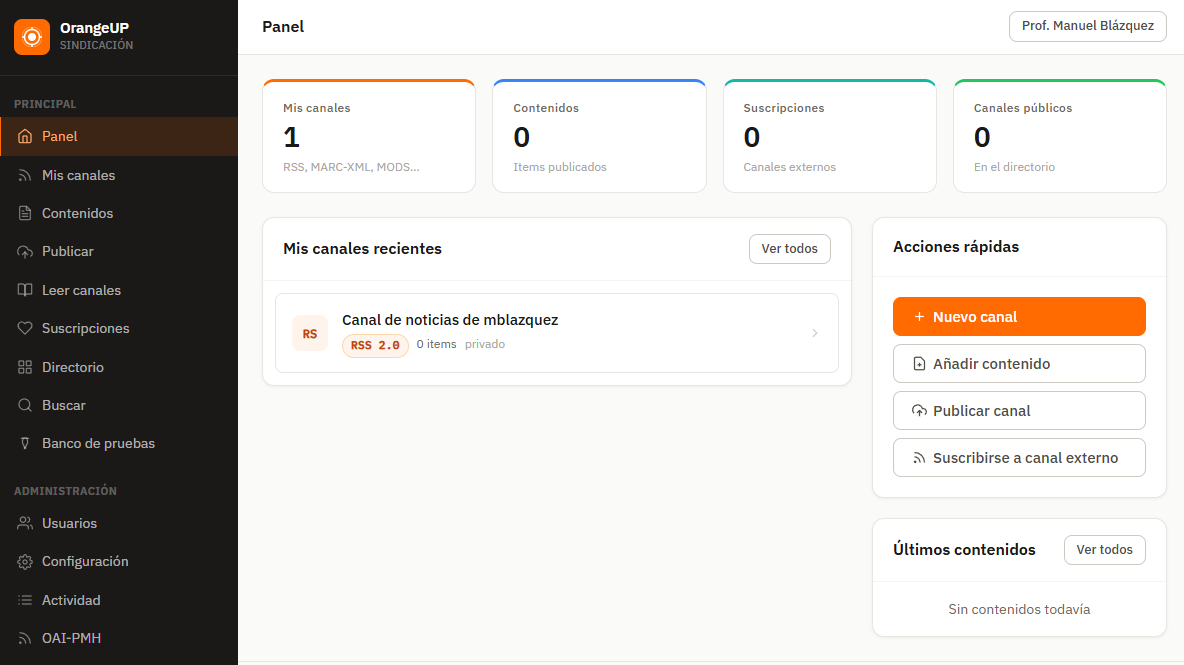
Demostrador de Procesos de Sindicación: OrangeUP
📅 7 nov 2011Sindicación de contenidos
La sindicación de contenidos es un proceso de comunicación y transmisión de datos ampliamente utilizado para efectuar el seguimiento de fuentes de información de forma sencilla y rápida. Dicho proceso requiere de programas capaces de generar canales de sindicación en formato XML y de otros capaces de leer dichos canales. Para que exista comunicación entre el emisor y el lector, ambos deben compartir y entender el lenguaje de codificación. En el caso de la sindicación, estos lenguajes derivados de XML son RSS 1.0, RSS 2.0 y ATOM.
En este punto cabe plantearse las siguientes preguntas:
¿Podría crearse un canal de sindicación con información bibliográfica?
¿Podrían emplearse formatos derivados de XML, como MARC-XML, para transmitir registros bibliográficos, archivísticos o documentales?
¿Las mismas técnicas de sindicación de contenidos pueden emplearse para otros formatos especializados?
Interfaz del demostrador OrangeUP
🍊 OrangeUP — Demostrador de sindicación documental
OrangeUP es un programa demostrador desarrollado expresamente para responder a estas preguntas, explicando el funcionamiento de las técnicas de sindicación, sus formatos y sus aplicaciones en el ámbito documental. Demuestra que el proceso de sindicación funciona exactamente igual para formatos bibliográficos especializados (como MARC-XML) que para RSS o ATOM.
La generación de canales de sindicación es un proceso que realiza automáticamente un programa adjunto a las herramientas de publicación digital (blogs, wikis, CMS y otros sistemas). Su ejecución se activa cuando se publican nuevos contenidos, regenerando un archivo XML que porta la información del canal.
En la práctica 5 se comprobará cómo trabajan este tipo de programas, verificando que su funcionamiento es idéntico tanto para formatos de sindicación tradicionales (RSS, ATOM) como para formatos especializados (MARC-XML). Con ello se demuestra empíricamente que el emisor del canal es siempre el mismo para cualquier tipo de formato.
Práctica 6: Lectura y Recuperación de Canales de Sindicación
📅 8 nov 2011Prácticas y trabajos
🔬 Descripción de la práctica
El segundo elemento esencial para demostrar un proceso de sindicación de contenidos es disponer de un lector de canales capaz de interpretar RSS 1.0, RSS 2.0 y ATOM. En la práctica 6 se demostrará de forma irrefutable que MARC-XML no solo puede generarse y compartirse como cualquier canal de sindicación, sino que también puede capturarse, recuperarse y leerse con un programa parser similar al utilizado para todos los demás formatos.
De esta forma se evidencia que la sindicación de contenidos puede emplearse para actividades bibliográficas, archivísticas, biblioteconómicas y documentales.
Sistemas de Recuperación Masiva basados en Sindicación de Contenidos
📅 8 nov 2011 · actualizado dic 2018Sindicación de contenidos
Las técnicas de lectura y recuperación de canales de sindicación hacen posible el desarrollo de una nueva generación de buscadores especializados, muy similares conceptualmente a los motores de búsqueda tradicionales (Google, Yahoo, Bing), pero muy distintos en cuanto a su alimentación contextual y corpus documental. La principal diferencia reside en la selección controlada de las fuentes de información, su descripción y recuperación de contenidos de forma exhaustiva y precisa.
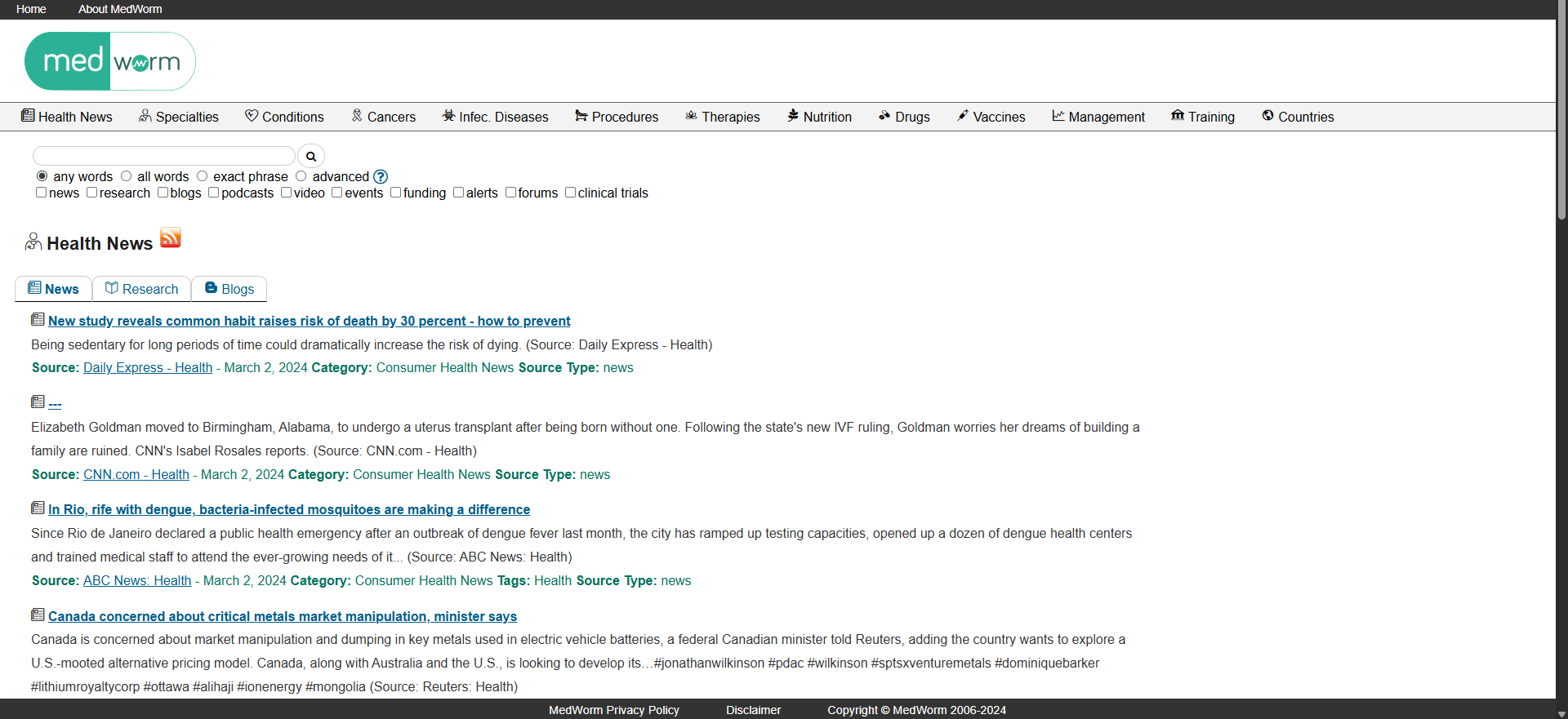
Un ejemplo de este tipo de buscadores especializados es MedWorm, un motor de búsqueda biomédico que agrega contenidos de miles de canales de sindicación especializados en medicina y ciencias de la salud. Una búsqueda en MedWorm resulta mucho más productiva para médicos y especialistas clínicos que una búsqueda equivalente en Google, porque el corpus documental está cuidadosamente seleccionado.
Interfaz de MedWorm — buscador especializado que agrega canales RSS/ATOM de fuentes biomédicas
Figura 7. Arquitectura de un sistema de recuperación masiva basado en sindicación de contenidos
La sindicación de contenidos es clave para las Ciencias de la Documentación no solo por su interés técnico, sino porque la mayor parte de los sitios web y sistemas de publicación digital disponen de un canal de sindicación paralelo. Esto significa que una enorme cantidad de información se genera constantemente de forma limpia, estructurada y accesible, cuyas fuentes pueden ser de gran importancia y relevancia científica.
Motores de recuperación a gran escala: Apache Lucene, Solr y Elasticsearch
Para sistemas de recuperación masiva con millones de documentos, MySQL FULLTEXT resulta insuficiente. Los motores de indexación de alto rendimiento resuelven esta limitación:
Apache Lucene: biblioteca Java de código abierto que implementa un motor de indexación y búsqueda a texto completo de alta eficiencia. Utiliza un fichero inverso optimizado, soporte para múltiples analizadores de texto (stemming, sinónimos, n-gramas), puntuación BM25 (evolución del modelo TF-IDF) y búsquedas difusas. Es la base tecnológica de prácticamente todos los buscadores empresariales modernos.
Apache Solr: servidor de búsqueda empresarial construido sobre Lucene. Añade una interfaz REST/HTTP, soporte para facetas (faceted search), resaltado de términos en resultados (highlighting), recomendaciones (MoreLikeThis), clustering con Carrot2 integrado y replicación distribuida.
Elasticsearch: motor distribuido también construido sobre Lucene, diseñado para escalabilidad horizontal en la nube. Utilizado por Wikipedia, GitHub, Netflix y la mayoría de las grandes plataformas de información.
Síntesis: del canal de sindicación al sistema de recuperación completo
Todo buscador especializado de esta naturaleza emplea de forma integrada las técnicas aprendidas a lo largo de esta asignatura:
Técnicas de sindicación y agregación de contenidos (RSS, ATOM, MARC-XML)
Procesamiento y normalización de texto (eliminación de stopwords, stemming, transliteración)
Indexación en bases de datos MySQL con FULLTEXT o en motores Lucene/Solr
Consultas SQL con operadores booleanos, LIKE, REGEXP y expansión de consulta
Agrupación automática de resultados por clustering (Carrot2, Lingo, k-means)
Presentación de resultados ordenados por relevancia TF-IDF o BM25
Sistemas de almacenamiento distribuido y clústeres de servidores para alta disponibilidad
Con estos fundamentos teóricos y prácticos se asienta la base necesaria para comprender, configurar, evaluar y, en su caso, desarrollar un sistema de recuperación de información documental especializado, capaz de operar sobre grandes volúmenes de fuentes heterogéneas con precisión y exhaustividad controladas.
📚 Referencias bibliográficas finales
BAEZA-YATES, R.; RIBEIRO-NETO, B. (2011). Modern Information Retrieval: The Concepts and Technology behind Search. 2.ª ed. Addison-Wesley.
MANNING, C. D.; RAGHAVAN, P.; SCHÜTZE, H. (2008). Introduction to Information Retrieval. Cambridge University Press. Disponible en: nlp.stanford.edu/IR-book
BLÁZQUEZ OCHANDO, M. (2011). Sindicación de contenidos: fundamentos y aplicaciones documentales. UCM.
GOLDENBERG, D. (2007). Categorización automática de documentos con mapas auto-organizados de Kohonen. Tesis de Magíster, ITBA.
§
Bibliografía y Recursos de Referencia
Referencia
Recuperación de información: fundamentos
BAEZA-YATES, R.; RIBEIRO-NETO, B. (2011). Modern Information Retrieval: The Concepts and Technology behind Search. 2.ª ed. Harlow: Addison-Wesley. ISBN 978-0-321-41691-9.
MANNING, C. D.; RAGHAVAN, P.; SCHÜTZE, H. (2008). Introduction to Information Retrieval. Cambridge: Cambridge University Press. Disponible en: nlp.stanford.edu/IR-book
SALTON, G.; MCGILL, M. J. (1983). Introduction to Modern Information Retrieval. New York: McGraw-Hill. ISBN 978-0-07-054484-0.
VAN RIJSBERGEN, C. J. (1979). Information Retrieval. 2.ª ed. London: Butterworths. Disponible en: dcs.gla.ac.uk
ROBERTSON, S.; ZARAGOZA, H. (2009). The Probabilistic Relevance Framework: BM25 and Beyond. Foundations and Trends in Information Retrieval, 3(4), 333–389.
Bases de datos y lenguaje SQL
CODD, E. F. (1970). A Relational Model of Data for Large Shared Data Banks. Communications of the ACM, 13(6), 377–387. DOI: 10.1145/362384.362685
DATE, C. J. (2004). An Introduction to Database Systems. 8.ª ed. Boston: Addison-Wesley. ISBN 978-0-321-18956-1.
WELLING, L.; THOMSON, L. (2017). PHP and MySQL Web Development. 5.ª ed. Addison-Wesley. ISBN 978-0-321-83389-1.
BLÁZQUEZ OCHANDO, M. (2011). Sindicación de contenidos: fundamentos y aplicaciones documentales. Madrid: UCM. Disponible en: mblazquez.es
WINER, D. (2002). RSS 2.0 Specification. Berkman Center for Internet & Society, Harvard University. Disponible en: rssboard.org/rss-specification
IETF (2005). The Atom Syndication Format. RFC 4287. Internet Engineering Task Force. Disponible en: tools.ietf.org/html/rfc4287
LIBRARY OF CONGRESS (2002). MARC 21 XML Schema. Washington: Library of Congress. Disponible en: loc.gov/standards/marcxml
HAROLD, E. R. (2004). Processing XML with Java. Boston: Addison-Wesley. ISBN 978-0-201-77186-2.
Clustering y clasificación automática
OSINSKI, S.; WEISS, D. (2005). A Concept-Driven Algorithm for Clustering Search Results. IEEE Intelligent Systems, 20(3), 48–54. DOI: 10.1109/MIS.2005.38
FIGUEROLA, C. G.; ALONSO BERROCAL, J. L.; ZAZO RODRÍGUEZ, A. F.; RODRÍGUEZ, E. (2002). Algunas técnicas de clasificación automática de documentos. Cybermetrics, 6/7(1). Disponible en: cybermetrics.cindoc.csic.es
GOLDENBERG, D. (2007). Categorización automática de documentos con mapas auto-organizados de Kohonen [Tesis de Magíster]. Buenos Aires: ITBA.
TAN, P.-N.; STEINBACH, M.; KUMAR, V. (2006). Introduction to Data Mining. Boston: Addison-Wesley. Cap. 8: Cluster Analysis. ISBN 978-0-321-32136-7.
SALTON, G.; WONG, A.; YANG, C. S. (1975). A Vector Space Model for Automatic Indexing. Communications of the ACM, 18(11), 613–620.
Motores de búsqueda y recuperación a gran escala
MCCANDLESS, M.; HATCHER, E.; GOSPODNETIĆ, O. (2010). Lucene in Action. 2.ª ed. Greenwich: Manning Publications. ISBN 978-1-933988-17-7.
GRAINGER, T.; POTTER, T. (2014). Solr in Action. Greenwich: Manning Publications. ISBN 978-1-617-29010-3.
GORMLEY, C.; TONG, Z. (2015). Elasticsearch: The Definitive Guide. O'Reilly Media. Disponible en: elastic.co — guide
BRIN, S.; PAGE, L. (1998). The Anatomy of a Large-Scale Hypertextual Web Search Engine. Computer Networks, 30(1–7), 107–117.
Sistemas de gestión de bibliotecas y documentación digital
REITZ, J. M. (2004). Dictionary for Library and Information Science. Westport: Libraries Unlimited. ISBN 978-1-591-58075-5.
ARMS, W. Y. (2000). Digital Libraries. Cambridge: MIT Press. ISBN 978-0-262-51111-2. Disponible en: cs.cornell.edu/wya/DigLib
BLÁZQUEZ OCHANDO, M. (2014). Fuentes de información y recuperación documental. Madrid: Dykinson. ISBN 978-84-9085-226-6.
CHOWDHURY, G. G. (2010). Introduction to Modern Information Retrieval. 3.ª ed. London: Facet Publishing. ISBN 978-1-856-04694-6.
ROWLEY, J.; HARTLEY, R. (2008). Organizing Knowledge: An Introduction to Managing Access to Information. 4.ª ed. Aldershot: Ashgate. ISBN 978-0-754-64431-6.